Mastering the Power of AI and Large Language Models for Business Success and Positive Social Impact
By Jochen Werne
Düsseldorf, 6 April 2023.
Throughout human history, transformative technological innovations have heralded new eras, reshaping our societies, economies, politics, and daily lives in ways previously unimaginable. The printing press, introduced by Johannes Gutenberg in the 15th century, serves as a profound testament to the sweeping power of innovation. Not just a tool for mass-producing books, the printing press birthed the dawn of widespread literacy, transforming workplaces as manual scribes became obsolete and creating new vocations in publishing and literature.
The press also catalyzed a socio-political upheaval. As literacy rates surged, so did the empowerment of the masses. Ideas, once confined to the elite, became accessible to many, seeding the Renaissance, and later, the Reformation. Niall Ferguson, in his seminal work, “The Square and the Tower,” eloquently captures this revolution, asserting that the printing press restructured historical hierarchies and networks, shifting power dynamics in unprecedented ways.[1]

In economic terms, the press laid the foundation for capitalist markets. As information became accessible, trade routes expanded, local businesses thrived, and a burgeoning middle class began to wield economic influence. On the societal front, with the proliferation of ideas came the Enlightenment, propelling societies towards principles of liberty, fraternity, and equality.
Fast forward to the close of the 20th century, and another innovation emerged as a harbinger of transformation: the internet. Much like the printing press, the internet redefined workplaces, rendering some jobs obsolete while spawning new professions in digital technology, e-commerce, and online content creation. The globalized economy we witness today, underpinned by intricate supply chains and instantaneous communication, owes its existence to the digital revolution.
Politically, the internet has both empowered and challenged established structures. Grassroots movements, from the Arab Spring to global climate change campaigns, have harnessed online platforms to mobilize support and challenge the status quo. However, it’s also provided a breeding ground for misinformation, deepening societal divides in certain instances.

Yet, as we stand on the cusp of the AI revolution, it’s crucial to reflect on lessons from our past. Both the printing press and the internet came with their boon and bane. Their essence wasn’t inherently good or bad; it was humanity’s application of these tools that rendered them so. As we navigate the realms of AI and Large Language Models (LLM), this adage holds truer than ever: Technology and technological inventions are neither good nor bad – it’s the way we use them that bestows upon them such attributes.
Chronicles of Code – Decoding the Magic Behind Large Language Models
The realm of artificial intelligence is undergoing rapid metamorphosis, and Large Language Models, such as GPT-3 and GPT-4, stand out as the front-runners in this transformation.[2] To truly appreciate the intricate tapestry of LLMs, one must delve deep into their foundational technologies, unravel the plethora of practical applications they enable, and critically evaluate the challenges they pose.

At the nucleus of LLMs is their technological backbone. These models owe their prowess to deep learning and, more specifically, the transformer architecture.[3] This intricate design enables them to sift through colossal amounts of data, synthesizing human-like text that often mirrors our nuanced thought processes. The primary education of these models stems from vast datasets spanning the breadth of the internet, but their true finesse is achieved when they’re fine-tuned using more focused datasets, enabling them to excel in specialized domains.[4]
When it comes to their application spectrum, LLMs have left indelible marks across sectors. In the labyrinthine world of research, where professionals are inundated with vast pools of data and intricate academic papers, LLMs emerge as lighthouses, offering clarity by summarizing and presenting key insights.[5] Language translation, a domain that’s been historically challenging due to the nuances and subtleties of human language, has seen remarkable enhancements with LLMs. They’ve added a layer of contextual depth that was previously lacking in traditional translation tools.[6] The educational sphere is undergoing a renaissance, thanks to LLMs. Their capabilities in offering personalized content, adapting to individual learning curves, and providing immediate feedback promise a future where learning is both tailored and transformative.[7]
Yet, every silver lining has a cloud. The inherent challenges of LLMs are subjects of extensive discourse. Their reliance on training data can be their Achilles’ heel — biases in training data can lead to prejudiced outputs, a significant concern given the widespread influence of AI.[8] Additionally, their textual outputs, while sophisticated, can sometimes lack true human understanding, leading to contextually skewed results.[9] The broader societal implications of LLM adoption, especially the potential displacement of jobs and questions of ethical accountability, are pressing concerns that demand attention.[10]
The tapestry of LLMs in real-world scenarios paints a vivid picture of their transformative potential. Customer service has seen an overhaul, with AI tools streamlining interactions and enhancing user experiences.[11] The corridors of journalism echo with the influence of LLMs, aiding in content creation, editing, and even pioneering new forms of storytelling.[12] The legal world, often bogged down by voluminous documents, benefits immensely from AI’s precision in document reviews, bringing efficiency and reducing human errors.[13]
As we segue into “Redefining Workflows: The Profound Influence of LLMs on the Modern Workforce,” we’ll delve deeper into the myriad ways LLMs are reshaping our professional landscapes.
A New Work Paradigm: LLMs’ Crucial Contribution to Contemporary Business Achievements
The release of Large Language Models has initiated a paradigm shift in our understanding of the workforce dynamics. The ground-breaking research presented in the paper titled “Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality,” authored by the illustrious team of researchers including Fabrizio Dell’Acqua, Edward McFowland III, Ethan Mollick, Hila Lifshitz-Assaf, Katherine C. Kellogg, Saran Rajendran, Lisa Krayer, François Candelon, and Karim R. Lakhani, brings forth significant insights into this transformation.
Praise is due to this team of researchers for conducting a well-structured, extensive experiment involving 758 consultants from the global management consulting firm, Boston Consulting Group (BCG). Their analysis offers invaluable insights into the applications and limitations of AI in knowledge-intensive tasks. The concept of a “jagged technological frontier” introduced in their paper signifies the nuanced capabilities of AI. It underscores the notion that while AI excels in certain tasks, others that might seem similar in complexity can be beyond its scope.
Their findings show that when consultants utilized AI in the realm of its capabilities, there was a noticeable uptick in productivity, with tasks being completed 12.2% more and 25.1% faster. The quality of results also soared, witnessing an impressive increase of over 40%. These figures paint a vivid picture of the transformative power of AI when applied within its domain of expertise. Yet, it’s essential to note that outside this domain, relying on AI may lead to counterproductive results.
The paper also identifies two distinct ways in which consultants engaged with AI. Some consultants acted as “Centaurs,” seamlessly dividing and delegating tasks between themselves and the AI, while others emerged as “Cyborgs,” integrating their workflows with the AI in an ongoing symbiotic interaction. Such observations are pivotal as organizations strive to harness the optimal potential of AI, while also understanding its limitations.
LLMs like ChatGPT, as highlighted in the research, have redefined the frontiers of automation, demonstrating capabilities in areas previously reserved for the most educated, creative, and highly paid workers. The research suggests that these models are more than mere tools; they are evolving entities with vast yet unpredictable capabilities. Their potential to transform workflows and elevate the quality of work output in the consulting realm, and possibly across other industries, is profound.
Yet, for all their potential, the research astutely underscores the risks associated with the blind adoption of LLMs. Misplacing trust in these systems for tasks outside their capabilities can lead to inaccurate results and compromise the integrity of the work. The inherent opacity of these models further complicates this dynamic. Without a clear understanding of their strengths and weaknesses, professionals may be navigating a minefield without a map.
The “jagged technological frontier” metaphor therefore poignantly encapsulates the ever-evolving landscape of AI capabilities. This invaluable research serves as a compass, guiding professionals and organizations on how to integrate LLMs efficiently into their workflows, optimize productivity, and elevate the quality of outputs. The ripple effects of LLMs on the workforce are profound, and as we traverse this technological frontier, it is paramount to tread with both enthusiasm and caution. The dedication and rigor of the research team in shedding light on this complex subject deserve commendation. Their work has undoubtedly laid a solid foundation for further exploration in the transformative world of AI and its implications on the workforce.[14]
The importance of discerning the “jagged technological frontier” concept is crucial. While some tasks may appear similarly intricate on the surface, not all can be executed efficiently by AI. Drawing from own research and the extensive studies by the German AI platform “Plattform Lernende Systeme“, it’s pivotal to distinguish which tasks are best tackled with human-AI collaboration.[15]
Harnessing the Power of LLMs: Best Practice approach from a global data insights market leader
Experian[16], as a global data leader, recognizes the transformative essence of information. Through AI and Machine Learning, Experian gleans significant insights from data, empowering businesses to make enlightened decisions. Additionally, the principle of ‘data for good’ resonates profoundly with the philosophy. By responsibly channeling data, the company not only catalyze economic progress but also mitigate societal challenges.
Experian has not only acknowledged the transformative potential of Machine Learning and Large Language Models but also fervently acted upon it.
Alex Lintner,[17] CEO of Experian Software Solutions, recently provided insights into the evolving role of artificial intelligence (AI) in the financial sector during a video conversation.[18] Lintner emphasized how AI, especially carefully constructed large language models, offer an unprecedented opportunity for the industry. He elucidated the scalability of such technologies, noting the potential to leverage machine learning for monitoring market trends and preempting credit risks as market circumstances change. This technological evolution allows machines to autonomously create prompts for decision makers, automate routine model monitoring processes, and even forecast variables that should be included in models in the future, thus enabling humans to channel their resources towards creating innovative solutions and supporting strategic initiatives.

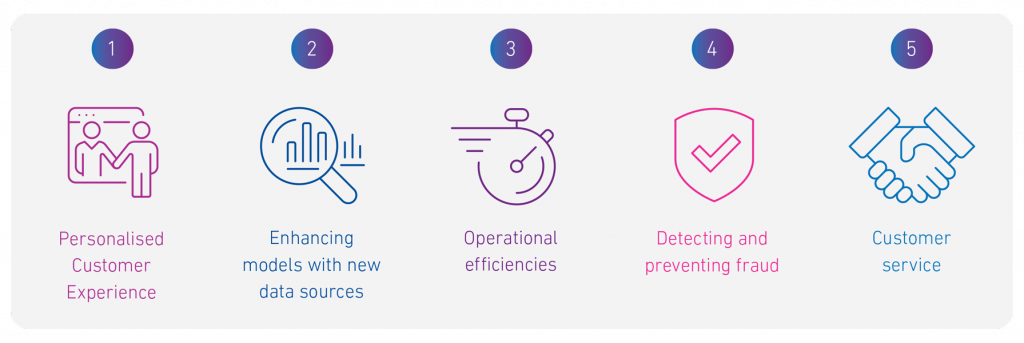
Moreover, Lintner shed light on the vast potential of AI in financial services. He highlighted the importance of agile risk detection and swift response mechanisms, indicating that this is just scratching the surface. Experian alone has pinpointed over 200 potential use cases. However, the immense capabilities of AI also beckon significant accountability. Lintner underscores the paramount need for rigorous compliance, governance, and transparency measures to guarantee AI’s ethical and judicious application.
On the ethical front, Lintner asserted, “Protecting data and ensuring responsible use of generative AI is not just a priority; it’s an imperative.” Given Experian’s pivotal role in handling sensitive financial information, establishing and maintaining trust is of utmost importance. Therefore, integrating stringent ethical standards, principles, and methodologies is crucial to the successful and responsible rollout of AI technologies.
As for steering the future, Lintner offers a clear roadmap: focus on acquiring talent in the AI domain, consistently gather customer feedback, and astutely prioritize opportunities. He believes that truly innovative solutions emerge from a profound understanding of customer necessities—a philosophy that resonates deeply in his perspectives.
In data companies globally every decision, every product, every innovation stems from the intricate understanding of the numbers. As the vast amounts of data they manage continue to grow, there’s an increasing need for more sophisticated ways to handle, analyze, and extract insights from it. Enter Machine Learning (ML) and, more specifically, Large Language Models (LLMs).
Ahead of the Curve: Cultivating a Workforce Fit for the Future
It’s important to understand that the use of LLMs isn’t just about improving backend processes; it’s especially about equipping the workforce for the future. When I took the helm on August 1st, 2023 as the new CEO of Experian DACH, one of the first directives on day one – inspired by the example of other Country Managers within the group – was to motivate all employees in Germany, Austria and Switzerland to undergo the corporate GenAI training. This wasn’t just a nod towards technological advancement; it was a strategic move to ensure that the very culture of the company was aligned with the digital transformation wave sweeping across industries.

By doing so, Experian isn’t merely training its employees on a new tool; it was nurturing a mindset of innovation and adaptability. With hands-on experience from the GenAI training, employees were encouraged to conceptualize practical roll-out use cases. For example, marketing professionals can incorporate insights from LLMs into their engagements, delivering more personalized and impactful messages to clients. In the meantime, the sales teams were able to use LLM-generated insights to identify potential markets or niches that had not yet been tapped – today, the vast majority of Experian employees worldwide are not only trained, but use GenAI in their daily work and develop new use cases on the fly.
Training and Learning is not just about immediate benefits. It is a forward-thinking strategy to ensure that new technologies, as LLMs continue to evolve and their applications grow, the company’s workforce would not be left behind. It is about fostering a culture of continuous learning, adaptability, and leveraging cutting-edge technology to stay ahead in highly competitive industries.
Redefining an Industry’s Future
Large Language Models (LLMs) like GPT-4 are at the forefront of the AI revolution, harnessing the capability to understand, generate, and augment human-like text at a scale previously unimaginable. This progression in AI has significant implications for businesses, especially for data-centric industries that are looking to derive actionable insights from vast data volumes.
One of the key challenges for data-centric companies is extracting meaningful insights from massive data sets. Traditional methods are often cumbersome, and while they can yield valuable results, the increasing volume, velocity, and variety of data have made these methods less efficient. Machine Learning offers a solution to this challenge. By leveraging algorithms that can learn from and make decisions based on data, ML has revolutionized the way companies interpret complex data structures.
Therefore, as data continues to be the backbone of our digital age, companies that can harness its power most effectively will lead the charge. For data insights giants like Experian, integrating Machine Learning, and especially Large Language Models, isn’t just a technological upgrade; it’s a transformative strategy to redefine their industry’s future.
Conclusion: The Harmonization of AI and Humanity
Throughout history, innovations have undeniably transformed societies, leaving a lasting impact on the course of human progress.[19] Whether we consider the revolutionary impact of the printing press or the transformative power of the internet, each technological leap has reshaped our world and the way we live. In the face of these profound changes, humanity has consistently demonstrated its ability to adapt, evolve, and harness these tools for our collective betterment.[20] In this context, artificial intelligence and with-it large language models emerges as the latest frontier where the intricate interplay between humans and technology is being examined and refined.

Rather than surrendering to the allure of extreme narratives, such as an AI-dominated dystopia or a utopian world of boundless prosperity, it is imperative to acknowledge that the future most likely rests within the delicate equilibrium of harmonizing AI and humanity.[21] This harmonization goes beyond mere coexistence; it encompasses collaboration and synergy, merging human intuition and the computational prowess of AI to create a potent force capable of driving profound transformations in all aspects of our lives.

As we venture further into this uncharted territory, the wisdom of great thinkers continues to guide us. Albert Einstein once remarked, “Imagination is more important than knowledge. For knowledge is limited, whereas imagination embraces the entire world, stimulating progress, giving birth to evolution”.[22] In the context of AI and humanity, this sentiment resonates profoundly. Our imagination and creativity serve as the catalysts for progress, and AI serves as the tool that can amplify and expedite our ability to transform imaginative ideas into reality.
The future may indeed be obscured by uncertainty, but it is unquestionably a future that we, as a collective humanity, possess the power to shape.[23] It is a canvas waiting for us to paint our hopes and aspirations upon, guided by principles of meticulous consideration and ethical responsibility.[24] The horizon of AI’s potential is expansive, and the possibilities it presents are as vast as the human imagination itself.
To achieve this harmonization, several key principles must be prioritized. First and foremost is ethics.[25] The development and deployment of AI must be grounded in a robust ethical framework that ensures fairness, transparency, and accountability. We must diligently guard against biases and discrimination, guaranteeing that AI benefits the entirety of humanity, leaving no one marginalized.[26]
Second, education and empowerment are paramount.[27] As AI becomes increasingly integrated into our daily lives, it is essential that individuals have access to the knowledge and skills necessary to navigate this new landscape. Education empowers us to harness AI’s potential while mitigating its associated risks.

Lastly, collaboration forms the linchpin of success.[28] Governments, businesses, researchers, and individuals must collaborate, transcending borders and sectors to harness the full potential of AI. Interdisciplinary collaboration can pave the way for breakthroughs that benefit society as a whole.
The harmonization of AI and humanity offers a promising path forward.[29] It is a journey that requires us to draw upon the wisdom of the past, the imagination of the present, and the ethical considerations of the future.[30] As we navigate this uncharted waters, we must remember that the power to shape our destiny resides within our collective hands.[31]
With knowledge, responsibility, and a harmonious integration of AI with human expertise, the future horizon is indeed one filled with promise and potential. It is a future where the partnership between humans and AI can lead to a brighter and more equitable world for all.
[1] Ferguson, N. (2018). The Square and the Tower: Networks and Power, from the Freemasons to Facebook. Penguin Press.
[2] Brown, T. B., et al. (2020). “Language Models are Few-Shot Learners.” OpenAI
[3] Vaswani, A., et al. (2017). “Attention is All You Need.” NeurIPS
[4] Devlin, J., et al. (2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” Google AI
[5] Chui, M., et al. (2018). “Notes from the AI frontier: Tackling Europe’s gap in digital and AI.” McKinsey Global Institute
[6] Hale, S. A. (2016). “Commercial Applications of Machine Translation.” The Oxford Handbook of Translation Studies
[7] Luckin, R. (2017). “Towards artificial intelligence-based assessment systems.” Nature Human Behaviour
[8] Bender, E. M., & Gebru, T. (2021). “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” Proceedings of FAccT.
[9] Lipton, Z. C., & Steinhardt, J. (2018). “Troubling Trends in Machine Learning Scholarship.” arXiv preprint
[10] Russell, S. (2019). “Human Compatible: Artificial Intelligence and the Problem of Control.” Viking
[11] Huang, M. H., & Rust, R. T. (2018). “Artificial Intelligence in Service.” Journal of Service Research
[12] Graefe, A. (2016). “Guide to automated journalism.” Tow Center for Digital Journalism, Columbia University
[13] Surden, H. (2014). “Machine Learning and Law.” Washington Law Review
[14] Dell’Acqua, F. et al. (2023). Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality. Harvard Business Review.
[15] acatech. Plattform Lernende Systeme (2023) https://www.plattform-lernende-systeme.de/home-en.html
[16] Experian Corporate website: https://www.experianplc.com
[17] About Alex Lintner: https://www.experianplc.com/about-us/board-and-senior-management/senior-management/alex-lintner/
[18] Lintner, A. (2023) Transforming Financial Services with AI and Automation – A video interview. YouTube https://youtu.be/_QnZf3FlNq0?si=Y4WditFgkX-aGaGt
[19] McKinsey Global Institute. (2021). “AI in the post-pandemic world: Five key trends.” https://www.mckinsey.com/capabilities/quantumblack/our-insights/global-survey-the-state-of-ai-in-2021
[20] Pew Research Center. (2019). “Americans and Privacy: Concerned, Confused and Feeling Lack of Control Over Their Personal Information.” https://www.pewresearch.org/internet/2019/11/15/americans-and-privacy-concerned-confused-and-feeling-lack-of-control-over-their-personal-information/
[21] World Economic Forum. (2020). “The Future of Jobs Report 2020.” https://www.weforum.org/reports/the-future-of-jobs-report-2020
[22] Einstein, A. (1931). “The Cosmic Religion: With Other Opinions and Aphorisms.”
[23] The Guardian. (2022). “The Uncertain Future of Artificial Intelligence.”
[24] World Economic Forum. (2018). “Ethics by Design: An Organizational Approach to Responsible Use of Technology.” https://www.weforum.org/whitepapers/ethics-by-design-an-organizational-approach-to-responsible-use-of-technology/
[25] The Royal Society and the British Academy. (2020). “Data Management and Use: Governance in the 21st Century.” https://royalsociety.org/topics-policy/projects/data-governance/
[26] AI Now Institute. (2019). “Discriminates in AI Hiring Tools and the Role of Human Oversight.” https://ainowinstitute.org/wp-content/uploads/2023/04/AI_Now_2019_Report.pdf
[27] UNESCO. (2020). “I’d Blush if I Could: Closing Gender Divides in Digital Skills Through Education.” https://unesdoc.unesco.org/ark:/48223/pf0000367416.page=1
[28] Stanford HAI. (2021). “AI Index 2021 Annual Report.” https://aiindex.stanford.edu/wp-content/uploads/2021/11/2021-AI-Index-Report_Master.pdf
[29] McKinsey & Company. (2018). “Notes from the AI Frontier: Insights from Hundreds of Use Cases.” https://www.mckinsey.com/~/media/mckinsey/featured%20insights/artificial%20intelligence/notes%20from%20the%20ai%20frontier%20applications%20and%20value%20of%20deep%20learning/notes-from-the-ai-frontier-insights-from-hundreds-of-use-cases-discussion-paper.ashx
[30] The Hastings Center. (2019). “Is Ethical AI an Oxymoron?” https://www.thehastingscenter.org/news/hastings-president-addresses-the-question-is-ethical-ai-an-oxymoron/
[31] United Nations. (2019). “The Age of Digital Interdependence.” https://digitallibrary.un.org/record/3865925?ln=en














 Author: Jochen Werne / 26.12.2023
Author: Jochen Werne / 26.12.2023