The Wirtschaftstag 2024, held on June 11 and 12 at the JW Marriott Hotel in Berlin, brought together high-profile speakers from business and politics. Germany stands at a crossroads, and now more than ever, bold market-economy ideas are needed for a strong Germany and Europe. The Social Market Economy is a centennial idea, inviting all who cherish freedom, believe in the creativity and inventiveness of citizens, respect property, and strive for performance and equal opportunity with social balance. However, the 75-year history of the Social Market Economy is also a constant battle to defend, maintain, and shape the economic order.
In this context, strong signals of shared responsibility from both business and politics are crucial to keeping the economy on track. These impulses have been set at the Wirtschaftstag 2024.
Key Highlights and The Role of Experian at Wirtschaftstag 2024
At Experian DACH, we were delighted to participate in this important event. As a subject matter expert in data and data insights, Experian played a significant role in the panel discussion on “Digitalization and AI – Transformation Opportunities for Business and Politics”. This participation underscores our commitment to leveraging data analytics to drive digital transformation, benefiting both businesses and society.
The esteemed panel participants were: Dr. Volker Wissing (Minister for Digital & Transport – MdB), Jochen Werne (CEO Experian DACH), Prof. Dr. Kristina Sinemus (Minister for Digital & Innovation, State Hesse – MdL), Petra Justenhoven (Speaker of the Board, PWC Germany) Marcel de Groot (CEO Vodafone Germany), Dr. Wolfgang Dierker (Managing Director Microsoft Germany), Hui Zhang (Managing Director NIO Europe), Carola Wahl (CEO DACH Nexi Group)
“We’re thrilled to make a joint contribution to the digital transformation journey and thereby strengthen Germany as a business location. We sincerely thank the Economic Council for this great opportunity!”
Jochen Werne, CEO Experian DACH
Perspectives and Gratitudes
A heartfelt gratitude has to go to to the organizers at the Wirtschaftsrat, especially Astrid Hamker and Wolfgang Steiger, for their dedication and leadership. Their efforts were instrumental in making Wirtschaftstag 2024 a resounding success and bringing together distinguished speakers as Friedrich Merz, MdB, Robert Habeck, MdB, Christian Lindner, MdB, Boris Pistorius, Bettina Stark-Watzinger, MdB, Dr. Volker Wissing, MdB, Dr. Marco Buschmann, MdB, Omid Nouripour, MdB, Dr. Carsten Linnemann, MdB, Alexander Dobrindt, MdB, Christian Sewing, René Obermann, Dr. Jens Weidmann
The international perspective was enriched by contributions from: Milojko Spajić, Prime Minister of Montenegro, Prof. Dr. Martin Kocher, Federal Minister for Labour and Economy of Austria, Aušrinė Armonaitė, Minister of Economy and Innovation of Lithuania
Personal Reflections
As I reflect on the Wirtschaftstag 2024, I am filled with a profound sense of gratitude and optimism. This year’s event, coming shortly after the European elections, carried a special significance. It served as a powerful signal of unity and forward-thinking, bringing together leaders from across the business and political spectrum to focus on the critical tasks ahead for a strong Germany and Europe.
A Platform for Meaningful Dialogue
The Wirtschaftstag 2024 was not just another event; it was the one of the largest Business and Politics gatherings in Germany. It provided an unparalleled platform for high-profile thought leaders and decision-makers to discuss and develop actionable recommendations for the future. The timing added an extra layer of importance, highlighting the need for bold market-economic ideas to secure the economic strength of Germany and the European continent.
The two days at the #Wirtschaftstag 2024 in Berlin have been a tremendous success, also for Experian. Engaging with high-profile participants from leading organizations and decision-makers from Germany’s business and political sectors has been truly inspiring.
Looking Forward
2024 marks several significant milestones: 75 years of the Grundgesetz and the Social Market Economy, over 30 years of the European Single Market, and the dawn of a new legislative period for the EU Parliament and Commission. These next few years will be crucial for the future competitiveness and viability of Europe.
I’m sure we all look forward to continuing this important dialogue and working together towards a prosperous future for Europe and beyond.
published on May 8, 2024 the below article in the original German version. Find the link HERE. Pictures used here are from private sources and Pixabay. Translation made by DeepL.com.
Throughout human history, transformative technological innovations have repeatedly led to impressive leaps in development that have reshaped our societies, economies, politics and daily lives in previously unimaginable ways.
The printing press developed by Johannes Gutenberg in the 15th century is a particular example of the far-reaching power of technological innovation. It was not only a tool for the mass production of books, but also ushered in the age of universal literacy. It has changed the world of work by making typists redundant and creating new professions in publishing and literature. Artificial intelligence (AI) is said to have a similarly revolutionary potential, and not just since large language models (LLM) such as OpenAI’s ChatGPT were established for the public to see. The extensive and immediately usable possibilities – such as the simplification of text generation or summarisation, coding – are inspiring. AI is about to fundamentally change the way we work today. But how do we deal with it?
The revolution through large language models: decoding their magic
At the forefront of this AI transformation are LLMs such as GPT-4. To truly understand their complex structure, one must dive deep into the underlying technologies, unravel the multitude of practical applications they enable and critically evaluate the challenges they pose. The range of applications of LLMs has already left an indelible mark on a wide variety of sectors. For example, LLMs are already creating new clarity in the confusing world of research through optimised summaries and presentations of key findings. LLMs are also leading to a paradigm shift in our understanding of work dynamics. The research report “Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality” describes this change and shows that the use of AI in a real-world work environment can lead to a significant increase in productivity: In this case, to 12.2 per cent more completed tasks and a 25.1 per cent reduction in processing time. These are impressive figures that illustrate the transformative power of AI even at today’s stage of development.
Utilisation of LLMs: Best practice approach
As a data insights company, Experian recognised the transformative essence of information early on. With the help of machine learning (ML), we gain important insights from data that companies can use to make informed decisions. In a recent video interview, Alex Lintner, CEO of Experian Software Solutions, explains the evolving role of AI in the financial sector and highlights the unprecedented opportunities that exist, particularly with carefully constructed large-scale language models.
Alex Lintner, CEO of Experian Software Solutions
Lintner explains the scalability of such technologies and the potential of using machine learning in monitoring market trends and anticipating credit risk. Technological advances are enabling machines to independently ask questions of decision makers, automate routine model monitoring processes and even predict which variables should be included in models in the future, allowing humans to focus their resources elsewhere.
In addition, Lintner highlights the enormous potential of AI for financial services, in particular agile risk detection and the associated ad hoc response management. As always, with great opportunity comes great responsibility: strict compliance, governance and transparency measures are urgently needed to ensure the ethical and sustainable use of AI. It is important to understand that the use of LLM’s is not just about improving back-end processes, but more importantly about equipping the workforce for the future. It is therefore mandatory for all Experian employees worldwide to complete the internal GenAI training programme. We see this – as well as all the other activities of our own Experian GenAI Academy – as important measures to keep our corporate culture in line with the wave of digital transformation rolling across industries.
Harmonisation of AI, business and society
Large-scale language models are now at the forefront of the AI revolution and have the ability to understand, generate and augment text, sound, images and video on a previously unimaginable scale. This has particular implications for all companies operating in data-centric industries, whose job it is to extract actionable insights from big data. Companies that utilise these opportunities for new data usage most effectively will gain market share in the future. For us, the integration of machine learning and large-scale language models in particular is not just a technological upgrade, but a comprehensive transformative strategy to reshape the future of our industry.
Innovation has always changed societies and had a lasting impact on the course of human progress. AI today represents the latest frontier where the complex interaction between humans and technology can be explored and refined. We therefore need to understand that our future most likely lies in the balance of harmonising AI and humans – a harmonisation that goes beyond mere coexistence: it involves collaboration and synergies that can merge human intuition and computing power into a powerful force that can drive profound change in all aspects of our lives.
To achieve this harmonisation, several key principles must be followed. Ethics come first. The development and use of AI must be based on a solid ethical foundation that ensures fairness, transparency and accountability. Prejudice and discrimination must be carefully avoided and it must be ensured that AI benefits all of humanity and excludes no one.
Second is education and skills. With the increasing integration of AI into our daily lives, it is important that individuals have access to the knowledge and skills they need to use this new technology. Education is key to realising the potential of AI while mitigating the associated risks. After all, collaboration is the key to success. Governments, businesses, researchers and citizens must work together across borders and sectors to realise its full potential. Interdisciplinary collaboration can pave the way for breakthroughs that benefit society as a whole.
With a strong focus on ethics, education and collaboration, we are able to create a future where AI and humans work in harmony and reach a new level of progress. This is a technological challenge, but also a societal one.
Mastering the Power of AI and Large Language Models for Business Success and Positive Social Impact
By Jochen Werne
Düsseldorf, 6 April 2023.
Throughout human history, transformative technological innovations have heralded new eras, reshaping our societies, economies, politics, and daily lives in ways previously unimaginable. The printing press, introduced by Johannes Gutenberg in the 15th century, serves as a profound testament to the sweeping power of innovation. Not just a tool for mass-producing books, the printing press birthed the dawn of widespread literacy, transforming workplaces as manual scribes became obsolete and creating new vocations in publishing and literature.
The press also catalyzed a socio-political upheaval. As literacy rates surged, so did the empowerment of the masses. Ideas, once confined to the elite, became accessible to many, seeding the Renaissance, and later, the Reformation. Niall Ferguson, in his seminal work, “The Square and the Tower,” eloquently captures this revolution, asserting that the printing press restructured historical hierarchies and networks, shifting power dynamics in unprecedented ways.[1]
In economic terms, the press laid the foundation for capitalist markets. As information became accessible, trade routes expanded, local businesses thrived, and a burgeoning middle class began to wield economic influence. On the societal front, with the proliferation of ideas came the Enlightenment, propelling societies towards principles of liberty, fraternity, and equality.
Fast forward to the close of the 20th century, and another innovation emerged as a harbinger of transformation: the internet. Much like the printing press, the internet redefined workplaces, rendering some jobs obsolete while spawning new professions in digital technology, e-commerce, and online content creation. The globalized economy we witness today, underpinned by intricate supply chains and instantaneous communication, owes its existence to the digital revolution.
Politically, the internet has both empowered and challenged established structures. Grassroots movements, from the Arab Spring to global climate change campaigns, have harnessed online platforms to mobilize support and challenge the status quo. However, it’s also provided a breeding ground for misinformation, deepening societal divides in certain instances.
Yet, as we stand on the cusp of the AI revolution, it’s crucial to reflect on lessons from our past. Both the printing press and the internet came with their boon and bane. Their essence wasn’t inherently good or bad; it was humanity’s application of these tools that rendered them so. As we navigate the realms of AI and Large Language Models (LLM), this adage holds truer than ever: Technology and technological inventions are neither good nor bad – it’s the way we use them that bestows upon them such attributes.
Chronicles of Code – Decoding the Magic Behind Large Language Models
The realm of artificial intelligence is undergoing rapid metamorphosis, and Large Language Models, such as GPT-3 and GPT-4, stand out as the front-runners in this transformation.[2] To truly appreciate the intricate tapestry of LLMs, one must delve deep into their foundational technologies, unravel the plethora of practical applications they enable, and critically evaluate the challenges they pose.
At the nucleus of LLMs is their technological backbone. These models owe their prowess to deep learning and, more specifically, the transformer architecture.[3] This intricate design enables them to sift through colossal amounts of data, synthesizing human-like text that often mirrors our nuanced thought processes. The primary education of these models stems from vast datasets spanning the breadth of the internet, but their true finesse is achieved when they’re fine-tuned using more focused datasets, enabling them to excel in specialized domains.[4]
When it comes to their application spectrum, LLMs have left indelible marks across sectors. In the labyrinthine world of research, where professionals are inundated with vast pools of data and intricate academic papers, LLMs emerge as lighthouses, offering clarity by summarizing and presenting key insights.[5] Language translation, a domain that’s been historically challenging due to the nuances and subtleties of human language, has seen remarkable enhancements with LLMs. They’ve added a layer of contextual depth that was previously lacking in traditional translation tools.[6] The educational sphere is undergoing a renaissance, thanks to LLMs. Their capabilities in offering personalized content, adapting to individual learning curves, and providing immediate feedback promise a future where learning is both tailored and transformative.[7]
Yet, every silver lining has a cloud. The inherent challenges of LLMs are subjects of extensive discourse. Their reliance on training data can be their Achilles’ heel — biases in training data can lead to prejudiced outputs, a significant concern given the widespread influence of AI.[8] Additionally, their textual outputs, while sophisticated, can sometimes lack true human understanding, leading to contextually skewed results.[9] The broader societal implications of LLM adoption, especially the potential displacement of jobs and questions of ethical accountability, are pressing concerns that demand attention.[10]
The tapestry of LLMs in real-world scenarios paints a vivid picture of their transformative potential. Customer service has seen an overhaul, with AI tools streamlining interactions and enhancing user experiences.[11] The corridors of journalism echo with the influence of LLMs, aiding in content creation, editing, and even pioneering new forms of storytelling.[12] The legal world, often bogged down by voluminous documents, benefits immensely from AI’s precision in document reviews, bringing efficiency and reducing human errors.[13]
As we segue into “Redefining Workflows: The Profound Influence of LLMs on the Modern Workforce,” we’ll delve deeper into the myriad ways LLMs are reshaping our professional landscapes.
A New Work Paradigm: LLMs’ Crucial Contribution to Contemporary Business Achievements
The release of Large Language Models has initiated a paradigm shift in our understanding of the workforce dynamics. The ground-breaking research presented in the paper titled “Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality,” authored by the illustrious team of researchers including Fabrizio Dell’Acqua, Edward McFowland III, Ethan Mollick, Hila Lifshitz-Assaf, Katherine C. Kellogg, Saran Rajendran, Lisa Krayer, François Candelon, and Karim R. Lakhani, brings forth significant insights into this transformation.
Praise is due to this team of researchers for conducting a well-structured, extensive experiment involving 758 consultants from the global management consulting firm, Boston Consulting Group (BCG). Their analysis offers invaluable insights into the applications and limitations of AI in knowledge-intensive tasks. The concept of a “jagged technological frontier” introduced in their paper signifies the nuanced capabilities of AI. It underscores the notion that while AI excels in certain tasks, others that might seem similar in complexity can be beyond its scope.
Their findings show that when consultants utilized AI in the realm of its capabilities, there was a noticeable uptick in productivity, with tasks being completed 12.2% more and 25.1% faster. The quality of results also soared, witnessing an impressive increase of over 40%. These figures paint a vivid picture of the transformative power of AI when applied within its domain of expertise. Yet, it’s essential to note that outside this domain, relying on AI may lead to counterproductive results.
The paper also identifies two distinct ways in which consultants engaged with AI. Some consultants acted as “Centaurs,” seamlessly dividing and delegating tasks between themselves and the AI, while others emerged as “Cyborgs,” integrating their workflows with the AI in an ongoing symbiotic interaction. Such observations are pivotal as organizations strive to harness the optimal potential of AI, while also understanding its limitations.
LLMs like ChatGPT, as highlighted in the research, have redefined the frontiers of automation, demonstrating capabilities in areas previously reserved for the most educated, creative, and highly paid workers. The research suggests that these models are more than mere tools; they are evolving entities with vast yet unpredictable capabilities. Their potential to transform workflows and elevate the quality of work output in the consulting realm, and possibly across other industries, is profound.
Yet, for all their potential, the research astutely underscores the risks associated with the blind adoption of LLMs. Misplacing trust in these systems for tasks outside their capabilities can lead to inaccurate results and compromise the integrity of the work. The inherent opacity of these models further complicates this dynamic. Without a clear understanding of their strengths and weaknesses, professionals may be navigating a minefield without a map.
The “jagged technological frontier” metaphor therefore poignantly encapsulates the ever-evolving landscape of AI capabilities. This invaluable research serves as a compass, guiding professionals and organizations on how to integrate LLMs efficiently into their workflows, optimize productivity, and elevate the quality of outputs. The ripple effects of LLMs on the workforce are profound, and as we traverse this technological frontier, it is paramount to tread with both enthusiasm and caution. The dedication and rigor of the research team in shedding light on this complex subject deserve commendation. Their work has undoubtedly laid a solid foundation for further exploration in the transformative world of AI and its implications on the workforce.[14]
The importance of discerning the “jagged technological frontier” concept is crucial. While some tasks may appear similarly intricate on the surface, not all can be executed efficiently by AI. Drawing from own research and the extensive studies by the German AI platform “Plattform Lernende Systeme“, it’s pivotal to distinguish which tasks are best tackled with human-AI collaboration.[15]
Harnessing the Power of LLMs: Best Practice approach from a global data insights market leader
Experian[16], as a global data leader, recognizes the transformative essence of information. Through AI and Machine Learning, Experian gleans significant insights from data, empowering businesses to make enlightened decisions. Additionally, the principle of ‘data for good’ resonates profoundly with the philosophy. By responsibly channeling data, the company not only catalyze economic progress but also mitigate societal challenges.
Experian has not only acknowledged the transformative potential of Machine Learning and Large Language Models but also fervently acted upon it.
Alex Lintner,[17] CEO of Experian Software Solutions, recently provided insights into the evolving role of artificial intelligence (AI) in the financial sector during a video conversation.[18] Lintner emphasized how AI, especially carefully constructed large language models, offer an unprecedented opportunity for the industry. He elucidated the scalability of such technologies, noting the potential to leverage machine learning for monitoring market trends and preempting credit risks as market circumstances change. This technological evolution allows machines to autonomously create prompts for decision makers, automate routine model monitoring processes, and even forecast variables that should be included in models in the future, thus enabling humans to channel their resources towards creating innovative solutions and supporting strategic initiatives.
Moreover, Lintner shed light on the vast potential of AI in financial services. He highlighted the importance of agile risk detection and swift response mechanisms, indicating that this is just scratching the surface. Experian alone has pinpointed over 200 potential use cases. However, the immense capabilities of AI also beckon significant accountability. Lintner underscores the paramount need for rigorous compliance, governance, and transparency measures to guarantee AI’s ethical and judicious application.
On the ethical front, Lintner asserted, “Protecting data and ensuring responsible use of generative AI is not just a priority; it’s an imperative.” Given Experian’s pivotal role in handling sensitive financial information, establishing and maintaining trust is of utmost importance. Therefore, integrating stringent ethical standards, principles, and methodologies is crucial to the successful and responsible rollout of AI technologies.
As for steering the future, Lintner offers a clear roadmap: focus on acquiring talent in the AI domain, consistently gather customer feedback, and astutely prioritize opportunities. He believes that truly innovative solutions emerge from a profound understanding of customer necessities—a philosophy that resonates deeply in his perspectives.
In data companies globally every decision, every product, every innovation stems from the intricate understanding of the numbers. As the vast amounts of data they manage continue to grow, there’s an increasing need for more sophisticated ways to handle, analyze, and extract insights from it. Enter Machine Learning (ML) and, more specifically, Large Language Models (LLMs).
Ahead of the Curve: Cultivating a Workforce Fit for the Future
It’s important to understand that the use of LLMs isn’t just about improving backend processes; it’s especially about equipping the workforce for the future. When I took the helm on August 1st, 2023 as the new CEO of Experian DACH, one of the first directives on day one – inspired by the example of other Country Managers within the group – was to motivate all employees in Germany, Austria and Switzerland to undergo the corporate GenAI training. This wasn’t just a nod towards technological advancement; it was a strategic move to ensure that the very culture of the company was aligned with the digital transformation wave sweeping across industries.
By doing so, Experian isn’t merely training its employees on a new tool; it was nurturing a mindset of innovation and adaptability. With hands-on experience from the GenAI training, employees were encouraged to conceptualize practical roll-out use cases. For example, marketing professionals can incorporate insights from LLMs into their engagements, delivering more personalized and impactful messages to clients. In the meantime, the sales teams were able to use LLM-generated insights to identify potential markets or niches that had not yet been tapped – today, the vast majority of Experian employees worldwide are not only trained, but use GenAI in their daily work and develop new use cases on the fly.
Training and Learning is not just about immediate benefits. It is a forward-thinking strategy to ensure that new technologies, as LLMs continue to evolve and their applications grow, the company’s workforce would not be left behind. It is about fostering a culture of continuous learning, adaptability, and leveraging cutting-edge technology to stay ahead in highly competitive industries.
Redefining an Industry’s Future
Large Language Models (LLMs) like GPT-4 are at the forefront of the AI revolution, harnessing the capability to understand, generate, and augment human-like text at a scale previously unimaginable. This progression in AI has significant implications for businesses, especially for data-centric industries that are looking to derive actionable insights from vast data volumes.
One of the key challenges for data-centric companies is extracting meaningful insights from massive data sets. Traditional methods are often cumbersome, and while they can yield valuable results, the increasing volume, velocity, and variety of data have made these methods less efficient. Machine Learning offers a solution to this challenge. By leveraging algorithms that can learn from and make decisions based on data, ML has revolutionized the way companies interpret complex data structures.
Therefore, as data continues to be the backbone of our digital age, companies that can harness its power most effectively will lead the charge. For data insights giants like Experian, integrating Machine Learning, and especially Large Language Models, isn’t just a technological upgrade; it’s a transformative strategy to redefine their industry’s future.
Conclusion: The Harmonization of AI and Humanity
Throughout history, innovations have undeniably transformed societies, leaving a lasting impact on the course of human progress.[19] Whether we consider the revolutionary impact of the printing press or the transformative power of the internet, each technological leap has reshaped our world and the way we live. In the face of these profound changes, humanity has consistently demonstrated its ability to adapt, evolve, and harness these tools for our collective betterment.[20] In this context, artificial intelligence and with-it large language models emerges as the latest frontier where the intricate interplay between humans and technology is being examined and refined.
Rather than surrendering to the allure of extreme narratives, such as an AI-dominated dystopia or a utopian world of boundless prosperity, it is imperative to acknowledge that the future most likely rests within the delicate equilibrium of harmonizing AI and humanity.[21] This harmonization goes beyond mere coexistence; it encompasses collaboration and synergy, merging human intuition and the computational prowess of AI to create a potent force capable of driving profound transformations in all aspects of our lives.
As we venture further into this uncharted territory, the wisdom of great thinkers continues to guide us. Albert Einstein once remarked, “Imagination is more important than knowledge. For knowledge is limited, whereas imagination embraces the entire world, stimulating progress, giving birth to evolution”.[22] In the context of AI and humanity, this sentiment resonates profoundly. Our imagination and creativity serve as the catalysts for progress, and AI serves as the tool that can amplify and expedite our ability to transform imaginative ideas into reality.
The future may indeed be obscured by uncertainty, but it is unquestionably a future that we, as a collective humanity, possess the power to shape.[23] It is a canvas waiting for us to paint our hopes and aspirations upon, guided by principles of meticulous consideration and ethical responsibility.[24] The horizon of AI’s potential is expansive, and the possibilities it presents are as vast as the human imagination itself.
To achieve this harmonization, several key principles must be prioritized. First and foremost is ethics.[25] The development and deployment of AI must be grounded in a robust ethical framework that ensures fairness, transparency, and accountability. We must diligently guard against biases and discrimination, guaranteeing that AI benefits the entirety of humanity, leaving no one marginalized.[26]
Second, education and empowerment are paramount.[27] As AI becomes increasingly integrated into our daily lives, it is essential that individuals have access to the knowledge and skills necessary to navigate this new landscape. Education empowers us to harness AI’s potential while mitigating its associated risks.
Lastly, collaboration forms the linchpin of success.[28] Governments, businesses, researchers, and individuals must collaborate, transcending borders and sectors to harness the full potential of AI. Interdisciplinary collaboration can pave the way for breakthroughs that benefit society as a whole.
The harmonization of AI and humanity offers a promising path forward.[29] It is a journey that requires us to draw upon the wisdom of the past, the imagination of the present, and the ethical considerations of the future.[30] As we navigate this uncharted waters, we must remember that the power to shape our destiny resides within our collective hands.[31]
With knowledge, responsibility, and a harmonious integration of AI with human expertise, the future horizon is indeed one filled with promise and potential. It is a future where the partnership between humans and AI can lead to a brighter and more equitable world for all.
[1] Ferguson, N. (2018). The Square and the Tower: Networks and Power, from the Freemasons to Facebook. Penguin Press.
[2] Brown, T. B., et al. (2020). “Language Models are Few-Shot Learners.” OpenAI
[3] Vaswani, A., et al. (2017). “Attention is All You Need.” NeurIPS
[4] Devlin, J., et al. (2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” Google AI
[5] Chui, M., et al. (2018). “Notes from the AI frontier: Tackling Europe’s gap in digital and AI.” McKinsey Global Institute
[6] Hale, S. A. (2016). “Commercial Applications of Machine Translation.” The Oxford Handbook of Translation Studies
[7] Luckin, R. (2017). “Towards artificial intelligence-based assessment systems.” Nature Human Behaviour
[8] Bender, E. M., & Gebru, T. (2021). “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” Proceedings of FAccT.
[9] Lipton, Z. C., & Steinhardt, J. (2018). “Troubling Trends in Machine Learning Scholarship.” arXiv preprint
[10] Russell, S. (2019). “Human Compatible: Artificial Intelligence and the Problem of Control.” Viking
[11] Huang, M. H., & Rust, R. T. (2018). “Artificial Intelligence in Service.” Journal of Service Research
[12] Graefe, A. (2016). “Guide to automated journalism.” Tow Center for Digital Journalism, Columbia University
[13] Surden, H. (2014). “Machine Learning and Law.” Washington Law Review
[14] Dell’Acqua, F. et al. (2023). Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality. Harvard Business Review.
He writes in his article: In an increasingly regulated market environment, providers who use their data intelligently will be the most successful, says Jochen Werne from Experian in an interview with FinanzBusiness.
Data is the new oil, they say: “The quality of data will become the kingmaker in the credit risk market of the future and open the way to new market opportunities,” says Jochen Werne, CEO of data service provider Experian DACH. In an increasingly regulated market environment, providers who use their data intelligently and master the balance between data protection and customer experience will be the most successful.
Werne names six “top challenges” for this year. These arise from regulations from the European Banking Authority (EBA) – and from technological developments. On the one hand, risk management is to be significantly improved and sustainability criteria verified at the behest of the European Central Bank and the EBA supervisory authority. On the other hand, artificial intelligence (AI) is opening up completely new opportunities in an increasingly complex market environment.
Original published in German by IT Finanzmagazin – find here. Translation provided by DeepL.com. Photos provided by Pixabay, Experian, Jochen Werne. Collage design by Canva
STRATEGY 23 January 2024
EBA deadline of 30 June: data quality will be decisive in the assessment of credit risks
Financial institutions are facing a significant change in the assessment of credit risks this year. Now comes 30 June: the deadline for new standards in credit risk assessment. Jochen Werne (CEO Experian DACH) is convinced that data quality will become the kingmaker in the credit risk market.
by Jochen Werne, CEO Experian DACH
Since 2021, financial service providers have been required to implement the supervisory priorities of the ECB and EBA. These priorities include the comprehensive improvement of credit risk management practices and the integration of new risk factors, particularly in the area of climate and the environment, into their risk management strategies. At the same time, the requirements for data management in the context of credit scoring are increasing. Artificial intelligence (AI) will play a key role here and banks will have to adapt to the new EU AI Act.
“By the deadline of 30 June 2024, large banks must have adapted their systems and infrastructures in accordance with the EBA Loan Origination and Monitoring Guidelines (EBA-GL LOM) for effective credit risk management and monitoring.”
This also includes closing data gaps. However, smaller, nationally supervised financial institutions must now also comply with these new guidelines, as additional elements of the 7th MaRisk amendment came into force on 1 January 2024, which are based on the EBA guidelines, among other things. Financial organisations must review their existing practices in 2024 and adapt their credit risk assessment standards accordingly. In future, credit assessment models will have to take much greater account of transparency, fairness and sustainability, particularly from an ESG perspective. The game changer for this is increasing their data quality.
All of this leads to five important changes:
1. Profitability strategies in a challenging market environment
“Investments in technologies such as generative AI and forward-looking risk management are becoming increasingly important.”
Advanced data analytics support organisations in various phases of their customer lifecycle. Already in the application phase, high data quality enables a more efficient assessment of creditworthiness. In portfolio management, advanced data analysis helps to proactively manage risks and dynamically manage the credit portfolio. Advanced analytics and high data quality help to strengthen resilience to risks, including data-based early risk identification and an optimised dunning and collection process.
2. Digitalisation for resilience, including against novel risks
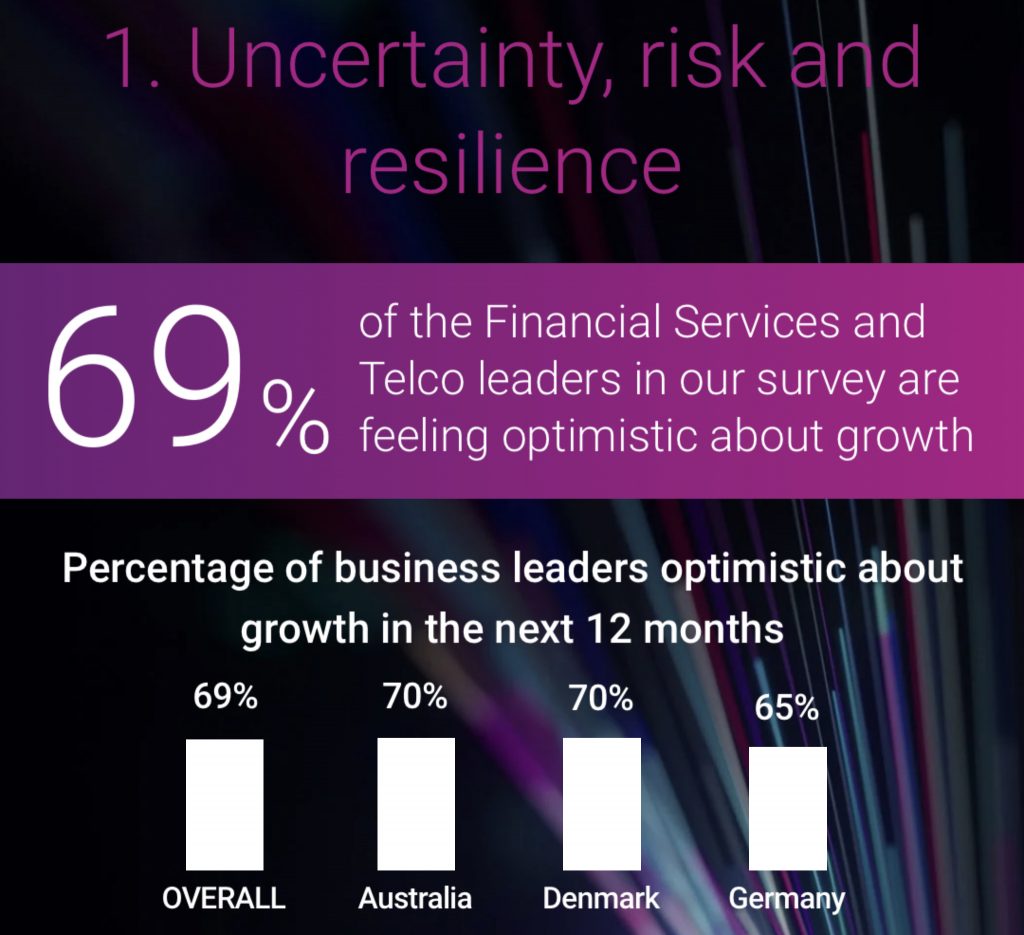
“Over the next 12 months, strengthening business resilience through automation and digitalisation will be key to responding to new risks such as AI, cyber threats and geopolitical tensions.”
These challenges not only affect the target customer landscape, but are also of great importance in the context of new ESG requirements. Due to their complexity and innovative nature, traditional approaches based on historical data cannot cope with these risks: Traditional approaches to data analysis and model preservation increasingly have to deal with slow regulatory processes on the one hand and a more dynamic macroeconomic environment and growing cyber risks on the other. In order to cope with this competitive situation, new strategies in the utilisation of all relevant data are urgently required, which place advanced analytics and the improvement of data quality at the centre.
3. PSD3, PSR and FIDA: Banks between risk and opportunity
As one of the players with the greatest wealth of data, this presents banks with a high risk in the face of new competitors. At the same time, however, it also offers them an opportunity to become a trusted partner for consumers. These regulations, which focus on the promotion of open banking services, greater control of data access and measures against online fraud, represent a starting point for financial institutions to think about the further use of transaction data. In addition to combating fraud, advanced analytics of transaction data, even taking into account all compliance requirements, opens up additional opportunities for interaction with end customers to improve the customer experience or the chance to monetise data.
4. Growth driver EU AI Act
“The EU AI Act will have a significant impact on the use of AI in the financial sector and further strengthen the financial sector’s technology focus.”
AI and machine learning (ML) will further automate decision-making processes in the future and strategic investments in this area will therefore become even more crucial for growth in the future. According to a study by Forrester Consulting commissioned by Experian, 60 per cent of German companies already take a similar view and have a comprehensive AI-based risk management programme in place. By using these technologies, credit and fraud risks can be assessed more precisely and efficiently, even in uncertain economic times. Companies that implement these developments are positioning themselves as pioneers in a rapidly developing, technology-driven financial sector: 78 per cent of the companies surveyed in the study in Germany also state that they are prioritising the use of further AI and ML applications.
5. Continuation of cloud migration in the financial world
“The ongoing implementation of continuous development and continuous improvement, particularly in the areas of business, analytics and IT, is becoming increasingly important.”
This includes identifying core business processes that will benefit significantly from cloud migration and defining clear priorities and objectives for the migration process. Cloud-based data analytics plays a central role in gaining valuable insights from customer behaviour, market trends and operational data to improve business processes and make more informed decisions.
—————————-
About the author: Jochen Werne has been CEO DACH at Experian since August 2023. Previously, he served as Managing Director at Prosegur Crypto and as Chief Development & Chief Visionary Officer at Prosegur, where he was responsible for the development and implementation of strategies in the areas of business development, innovation and international sales. Werne’s career includes significant leadership positions at Bankhaus August Lenz & Co. AG, Mediolanum Banking Group, where he served as Director and Authorised Representative and was instrumental in the company’s digital business transformation. His academic career includes a FinTech programme at the University of Oxford (2017-2018) and a Diploma in International Banking at Goethe University Frankfurt (1997-2000).
The rise of AI and ML in fraud prevention can lead to a new era of digital trust and compliance
Author: Jochen Werne / 26.12.2023
In an era marked by rapidly advancing technology and increasing global interconnectivity, the fight against online fraud has become a paramount concern for financial institutions, businesses, and regulators worldwide. Part of my professional work revolves around understanding and mitigating the risks associated with financial fraud. The Experian Forrester Fraud Research Report 2023, which was recently released, sheds light on the escalating threat of online fraud and the evolving strategies to counter it, particularly through the use of Machine Learning (ML) and Artificial Intelligence (AI).
The report’s findings are stark: a 74% increase in fraud losses in Germany, reflecting nearly the global increase rate. This surge is not just a statistic; it’s a clear indication of the sophisticated and pervasive nature of modern financial fraud. Companies across various sectors are feeling the impact, with financial services bearing the brunt. This trend is deeply concerning not only for the economic health of individual businesses but also for the broader stability and security of the financial system.
From a geopolitical perspective, the rise in online fraud is a multifaceted challenge. It’s a threat that transcends borders, affecting relations among nations, and has become a significant factor in international policy and security discussions. Countries, including Germany, are increasingly recognising the need for cooperative international efforts to combat this scourge. The geopolitical implications are profound, as fraud undermines economic stability and erodes public trust.
Turning to the German banking sector, the issue of compliance and reputation risk under the framework of Minimum Requirements for Risk Management (MaRisk) is particularly pertinent. Banks are finding themselves at the forefront of the battle against online fraud, necessitating robust risk management strategies that align with regulatory requirements. Under MaRisk, the mandate is clear: implement effective, comprehensive controls to detect, prevent, and manage fraudulent activities. The reputational risk for banks and their board members is immense; a single lapse can lead to significant financial losses, legal consequences, and lasting damage to customer trust.
In this challenging landscape, AI/ML-based fraud prevention methods stand out as beacons of hope. These technologies offer the promise of enhancing detection capabilities, reducing false positives, and adapting swiftly to new fraudulent tactics. However, their implementation must be undertaken with a clear understanding of the ethical implications and potential biases inherent in AI systems. As we embrace these technologies, we must also commit to transparency, accountability, and continuous improvement to ensure they serve the interests of all stakeholders fairly and effectively.
Despite the challenges, I believe there is a path forward that balances the need for security with the imperative for innovation and growth. The key lies in embracing a multi-faceted approach to fraud prevention that leverages the best of technology, human expertise, and regulatory compliance. ML, with its ability to learn and adapt to new patterns, offers a powerful tool in this fight. However, its effectiveness hinges on the quality of data, the integrity of algorithms, and the wisdom of the humans who guide its evolution.
The German companies surveyed in the study are acutely aware of the challenges and opportunities presented by AI/ML in fraud prevention. The overwhelming majority recognise the efficacy of ML-based approaches and anticipate their increasing dominance in the field. Yet, they also acknowledge the hurdles, including the costs associated with deploying advanced fraud prevention solutions, the need for continuous adaptation, and the importance of addressing the ethical considerations of AI use.
In my experience, one of the most critical factors for success in this endeavour is collaboration. Tackling online fraud is a collective effort that requires the involvement of businesses, regulators, technology providers, and consumers. By working together, sharing knowledge, and fostering a culture of innovation and vigilance, we can stay ahead of fraudsters and protect the integrity of our financial systems.
Another vital aspect is education and awareness. Both consumers and employees must be informed about the risks of online fraud and the steps they can take to prevent it. Regular training, robust policies, and a culture of security are essential in creating a resilient defense against fraud.
Finally, we must recognize that the fight against fraud is an ongoing battle. As technology evolves, so too will the tactics of fraudsters. We must remain agile, constantly updating our strategies, investing in new technologies, and adapting to changing regulatory landscapes. This dynamic approach is not just about defense; it’s about building a stronger, more secure future for everyone.
The Experian Forrester Fraud Research Report 2023 is a call to action. It highlights the urgent need for enhanced strategies, stronger collaboration, and a steadfast commitment to ethical, innovative solutions in the fight against online fraud. As leaders in the financial services industry, we have a responsibility to take the helm, steering our organisations towards safer waters in this tumultuous sea of digital threats. By harnessing the power of AI/ML, prioritising ethical considerations, and fostering a culture of collaboration and continuous learning, we can not only mitigate the risks of online fraud but also pave the way for a more secure, prosperous, and trustworthy financial ecosystem.
From the eloquent words of Shakespeare in Henry V, where he once proclaimed, “all things are ready if our minds be so”^1 to the monumental shifts brought by Gutenberg’s printing press^2, history reminds us that change is both an inevitable and defining characteristic of human progress. As the world stands at the threshold of a new epoch marked by rapid technological shifts and pronounced geopolitical transformations, this profound sentiment compels us to reflect on the paramount importance of preparedness and perspective. The way societies respond to these shifts determines the direction of their trajectory. In our current age, Europe finds itself at the nexus of global transformations driven by technological advancements and geopolitical tectonics.
Technology: A Historical Reflection
Peering through the lens of history, one quickly realizes that technology has been both a beacon of hope and an augury of upheaval. Take the 15th century’s monumental invention of the printing press as a case in point^2. This groundbreaking innovation democratized access to information and catalysed a substantial uptick in literacy rates across Europe. As Eisenstein posits, the “Printing Revolution” catalyzed an era where knowledge was no longer the privilege of the few but a right of the many^2. Yet, its reverberations were not confined to just reading and writing. The press became the vessel through which Martin Luther disseminated his Ninety-Five Theses, triggering a religious revolution that reshaped the European continent.
However, the journey wasn’t without turbulence. This democratization of knowledge played a pivotal role in challenging the established order, culminating in events like the Reformation, which MacCulloch describes as Europe’s great house divided^3.
Niall Ferguson, in “The Square and the Tower”, beautifully illustrates the timeless tension and interplay between networks and hierarchies^4. Historically, technologies like the printing press have emerged as disruptors, challenging established orders and reshaping hierarchies. The press, for instance, allowed for the free flow of ideas, becoming an early network that democratized information. Yet, not everything it propagated was for the betterment of society. The infamous “Malleus Maleficarum”, an ostensibly scholarly treatise, fueled the flames of the European witch hunts, leading to persecution, paranoia, and a dark chapter in history^5.
From Past to Present: The Tech Geopolitical Nexus
Fast forward to the present, and we witness a world where technology continues to shape geopolitical realities. Maddison’s macro-economic study reveals that the global center of economic gravity has been steadily shifting towards the East, particularly since the dawn of the 21st century^6. Nowhere is this shift more apparent than in the realm of technology.
The US-China tech rivalry, explored by Fuller, highlights the strategic challenges posed by China’s technological ascent^7.
The race for supremacy in AI, quantum computing, 5G, and biotechnologies marks the modern-day power play. But this isn’t merely about technological one-upmanship; it signifies a larger canvas of geopolitics, economics, and even societal values.
Many analysts are drawing parallels to the Cold War, coining the term “Tech Cold War” or “Cold War II”. Unlike the 20th-century version, primarily characterized by nuclear deterrence between the USSR and the US, this new Cold War positions the US and China in an intense rivalry for technological, economic, and military dominance. In the midst of this rivalry, both nations are hyper-aware of the stakes.
Navigating the Waters of New Geopolitical Paradigms
More than a century ago, the naval strategist Alfred Thayer Mahan, in his seminal work on sea power, postulated that maritime dominance was crucial to national greatness.
Today the Indo-Pacific has become the focal point of 21st-century geopolitics. Here, China’s assertive ‘Two Ocean Strategy’ is emblematic of its ambitions to exert influence both in the Pacific and the Indian Ocean. This expansive maritime vision is not just about sea lanes and trade; it’s a reflection of China’s aspirations to be a global power.
Simultaneously, the Taiwan question looms large in this maritime strategy. Its strategic location in the first island chain poses both an opportunity and a challenge for Beijing. Control over Taiwan would offer unencumbered access to the broader Pacific.
However, the rise of one power often brings countermeasures by others. The ‘AUKUS’ agreement between Australia, the United Kingdom, and the United States is a manifestation of this dynamic. While cloaked in the language of technological collaboration, especially in the realm of nuclear-powered submarines, the underlying intent of AUKUS is clear. It seeks to counterbalance China’s growing naval capabilities and assertiveness, particularly in the South China Sea.
Reflecting on Mahan’s sea power doctrine in this context provides a sobering perspective. Mahan believed that maritime dominance was the linchpin of global influence. Yet, he also understood the responsibilities and challenges that came with such power. In our contemporary setting, while nations pursue their maritime strategies, it is imperative they also embrace the principles of dialogue, cooperation, and conflict avoidance.
Taiwan epitomizes this interplay. As a beacon in semiconductor manufacturing, Taiwan’s geopolitical relevance can’t be overstated. Any instability could trigger economic consequences potentially dwarfing the aftermath of the Covid-19 pandemic^9.
Taiwan and Europe: Quietly Interwoven, Profoundly Connected.
In the intricate web of global technology supply chains, few names stand out as prominently as Taiwan Semiconductor Manufacturing Company (TSMC). Founded in 1987, TSMC has ascended the technological hierarchy to become the world’s leading semiconductor foundry, a testament to its unwavering commitment to innovation and excellence.
TSMC’s significance is multifaceted. For one, it’s the world’s largest dedicated independent semiconductor foundry^8. With clients ranging from major tech giants like Apple and Nvidia to burgeoning startups, TSMC’s production underpins a vast swathe of the digital products and solutions we rely on daily. However, TSMC’s role isn’t merely a commercial or technological one. It is geopolitical. With the escalating “Tech Cold War” between the U.S. and China, TSMC finds itself at an intriguing junction. The company’s strategic importance is underscored by global reliance on its cutting-edge chip manufacturing capabilities. This reliance has not only made TSMC a coveted partner but also a strategic asset in the larger scheme of global geopolitics. The U.S. push to ensure TSMC sets up manufacturing bases on its soil, and China’s keen interest in the semiconductor sector, highlights the foundry’s pivotal position.
Furthermore, TSMC embodies Taiwan’s broader significance in the tech world. As the geopolitical tussle intensifies, Taiwan – and by extension, TSMC – becomes a linchpin for global tech supply chains. A disturbance in TSMC’s operations, as speculated, could have cascading ramifications across industries, from consumer electronics to automotive and healthcare. Any significant disruption in this intricate supply chain would reverberate globally, with experts suggesting a potential 5% drop in global automotive production^9.
As chips become smaller, denser, and more powerful, the precision and capability of lithography machines must evolve in tandem.
Here’s where Europe and ASML, a Dutch gem, comes into play. The company is the sole producer of extreme ultraviolet (EUV) lithography machines^8, an advanced technology that allows for the creation of incredibly dense and efficient chips. With transistors now approaching atomic scales, EUV lithography is no less than a technological marvel, allowing chipmakers to etch circuits just a few nanometers wide.
However, the conversation around ASML isn’t merely about technological mastery. Given its unique position as the only producer of these EUV machines, ASML enjoys a quasi-monopolistic status in this niche yet profoundly impactful domain. In an era where technological supremacy is increasingly intertwined with geopolitical power, also ASML’s importance cannot be overstated. The machines they produce are not just expensive and sophisticated pieces of equipment; they are, in many ways, gatekeepers to the next generation of digital innovation.
Such a near-monopoly naturally draws attention. Nations and corporations are keenly aware of the strategic value inherent in controlling or accessing state-of-the-art chipmaking technology. With the ongoing technological cold war, where semiconductor supply chains have become part of the geopolitical chessboard, ASML finds itself in a spotlight it never sought but cannot avoid.
Europe’s Crucial Pivot
Europe’s position in this evolving tech landscape is unique. While traditionally viewing the Atlantic alliance as a cornerstone of its foreign policy, the rise of China necessitates a recalibrated approach^10. Europe’s interlinked trade with China, especially through critical chokepoints like the Malacca Strait, underscores the strategic dimension of this relationship^11.
In this whirlwind of technological and geopolitical flux, Europe is not an idle spectator. With a collective GDP nearing $22 trillion, it wields considerable influence. Europe’s role is multi-dimensional: an economic powerhouse, a voice of reason in tumultuous times, and often a mediator in global disputes.
The ECB recognizes that the financial institutions it oversees must adapt to these transformative times. A crucial element of this adaptation is embracing digitalization, with a special emphasis on robust data-driven risk management.
Strengthening Resilience: The intricate web of global economies translates to shared vulnerabilities. It’s imperative for Europe’s financial edifice to be robust, equipped to handle external shocks, and maintain systemic stability.
Digitalisation & Institutional Strengthening: The burgeoning fintech sector necessitates a complete metamorphosis for legacy banks. This isn’t a mere cosmetic digital overhaul. Banks need to internalize and deploy intelligent digitalization. Central to this transformation is data analytics, supercharged by AI. Harnessing data, drawing meaningful insights, and predicting trends will determine who thrives in this new era.
Climate Change Initiatives: Europe has consistently championed sustainability. The financial sector’s alignment with green, sustainable practices isn’t just altruistic; it’s also economic prudence, ensuring long-term viability and stability.
The above mentioned ECB focus is highlighted by Experian’s 2023 report on why AI-driven, regulatory-compliant analytics solutions are becoming imperative for European banks^13.
The AI Paradigm: Europe’s value-based Ethical Approach
Europe’s approach to AI regulation, championing the cause of ‘explainable AI’, shows its commitment to integrating technology with ethics. This dedication harks back to its legacy of literacy and the importance of accessibility, a theme explored by Graff^14. As Europe navigates the ‘Asian Century’^15, it does so with a clear vision: to leverage its historical experiences and chart a course that balances innovation with ethical considerations. The European AI Act encapsulates this approach. The Act’s core philosophy revolves around ensuring AI applications are safe and respect existing laws and values. This includes transparency obligations, strict criteria for ‘high risk’ AI applications, and a provision for setting up a European Artificial Intelligence Board.
One might wonder, why the emphasis on explainability? As AI systems permeate critical sectors, from healthcare to finance, their decisions can profoundly impact individuals. An ‘explainable AI’ ensures that these decisions are not just accurate but also comprehensible to the average person. This empowers individuals, fostering trust in AI systems.
The Act, however, isn’t just about explainability. It recognizes the diverse applications of AI and categorizes them based on risk. For ‘high-risk’ applications, stringent requirements, from transparency to accuracy and security, are mandated. This stratified approach ensures that while innovation isn’t stifled, critical areas receive the scrutiny they warrant.
Economic Powerhouses: A Comparative Analysis
Any discussion on global transformation would be incomplete without examining the economic engines driving these changes. China’s astounding growth, with a GDP of $17.7 trillion by 2022^16, and its decade-long average annual growth rate of 6.5%, contrasts with the US’s $25.3 trillion GDP and a more conservative 2.3% growth rate^17. The European Union, showcasing resilience and integration, clocks a collective GDP nearing $22 trillion^18, with trade figures underscoring its global economic clout^19.
Conclusion: Europe’s Way Forward
Our world is in a state of flux, reminiscent of those transformative moments in history. From the monumental shifts of the Printing Revolution^2 to the divisive yet transformative Reformation^3, Europe has witnessed and shaped global trajectories. As it stands at the crossroads of another transformation, it draws from its rich historical tapestry, aiming to strike a balance between embracing the future and preserving its core values.
The digital future beckons, but it’s not without its challenges. Whether it’s the complex web of tech geopolitics or the imperative of sustainable growth, Europe’s journey forward will need to be both adaptive and principled. At the heart of this journey lies the potent combination of data and ethics. And as Europe strides into the future, it carries with it a clear message: progress, when rooted in ethics and driven by knowledge, can usher in an era that’s not just technologically advanced but also just, balanced, and peaceful.
Footnotes:
^1 Shakespeare, William. “Henry V.” Act IV, Scene 3. ^2 Eisenstein, Elizabeth L. “The Printing Revolution in Early Modern Europe.” Cambridge University Press, 1983. ^3 MacCulloch, Diarmaid. “Reformation: Europe’s House Divided 1490-1700.” Penguin UK, 2004. ^4 Ferguson, Niall. “The Square and the Tower: Networks and Power, from the Freemasons to Facebook.” Penguin, 2018. ^5 Kramer, Heinrich and Sprenger, James. “Malleus Maleficarum.” Dover Publications, 1971. ^6 Maddison, Angus. “Contours of the World Economy 1-2030 AD: Essays in Macro-Economic History.” Oxford University Press, 2007. ^7 Fuller, Douglas B. “Cutting off our nose to spite our face: US policy toward Huawei and Taiwan in the shadow of the Chinese tech challenge.” International Security 45.3 (2021): 52-89. ^8 Chappell, Bill. “ASML: The Obscure Dutch Company That’s Enabling Big Advances In Tech.” NPR, 2019. ^9 “The Economic Impact of a Taiwan Crisis.” Nikkei Asia, 2023. ^10 Casarini, Nicola. “The Rise of China and the Future of the Atlantic Alliance.” Oxford University Press, 2020. ^11 Lanteigne, Marc. “China’s Maritime Security and the ‘Malacca Dilemma’.” Asian Security 4.2 (2008): 143-161. ^12 “European Central Bank Annual Report.” 2023. ^13 Experian PLC. “Annual Report and Financial Statements.” 2023. ^14 Graff, Harvey J. “The Legacies of Literacy: Continuities and Contradictions in Western Culture and Society.” Indiana University Press, 1987. ^15 Khanna, Parag. “The Future is Asian: Commerce, Conflict, and Culture in the 21st Century.” Simon and Schuster, 2019. ^16 “World Bank Data: China.” 2022. ^17 “World Bank Data: United States.” 2022. ^18 “World Bank Data: European Union.” 2022. ^19 “European Commission Trade Statistics.” 2022.
About the author
Jochen Werne is CEO of Experian DACH. Large-scale global data powerhouses like Experian with it’s more than 20.000 data and analytics experts and a market cap of nearly €30bn have a pivotal role to play in this evolving narrative. As a global vanguard in data analytics, Experian is uniquely poised to offer financial institutions the insights and tools essential for navigating the multifaceted challenges of our times. In a world inundated with data, discerning patterns, understanding trends, and anticipating potential pitfalls will be the linchpin of success.
I had the distinct honor, alongside CCO Björn Hinrichs, to represent Experian DACH at the Gala event 2023. Our heartfelt gratitude goes to acatech for their warm invitation.
It’s clear that fostering a robust relationship between science and industry is paramount. The National Academy of Science and Engineering stands as a beacon, guiding and correcting, making technological innovation the cornerstone of transformation. This union of strong research, pioneering companies, and forward-thinking policies is the backbone of what acatech and countless others strive for. In this journey, while competition fuels our drive, it is cooperation that offers the platform for greatness.
In the infinite expanse of space, we are but astronauts on a tiny speck called Earth. Regardless of our political and geopolitical landscape, science and research must always be the bridge, the “Bridge over Troubled Water” that connects us and ensures progress, says Jan Wörner, President of acatech, wisely.
In reflecting on this, Germany’s Federal President Frank-Walter Steinmeier’s words resonate deeply: “I think we should base our perspective more on Max Frisch and trust ourselves as individuals and society alike to be able to shape the future. And that means developing perspectives, broadening our horizons and, yes, always daring to try something new. We need all this in the phase of upheaval we are in. Holding on to the past, ignoring change, refusing change, that is not an option – especially not in an open society like ours. But: We have to give change – that is the task of politics, business and science – a direction!”
Drawing from these profound insights and looking through the lens of our work at Experian DACH, the era we are entering can be aptly described as a new Age of Enlightenment, where data and therefore data literacy is paramount. As the Enlightenment thinker Voltaire astutely pointed out, “Judge a man by his questions rather than by his answers.” It’s a sentiment that is even more relevant today. Taking cues from Immanuel Kant’s wisdom, enlightenment is about emerging from our limitations. In the context of our time, achieving data literacy and harnessing data effectively signifies our evolution from technological naivety.
While AI stands as a monumental tool to decipher this data, its effectiveness lies in the quality of the data it is fed. It brings to the fore the urgent need for data literacy. An AI is only as good as its data. Thus, a distorted understanding could lead to distorted outputs. The onus is on us, leaders in data, to champion the responsible use of AI and advance the narrative on the symbiotic relationship between data and AI.
This new Enlightenment is our journey towards an era where society is mature and informed, utilizing the strength of data and AI for the betterment of all. Knowledge, in this context, isn’t just power but the foundation for positive societal transformation.
Concluding with my personal reflection, data isn’t merely a quantified entity; it’s a potent instrument to comprehend and address pressing challenges. Our collective aim should be to cultivate an understanding of data – its collection, utilization, and, importantly, its ethical application.
Our commitment at Experian DACH, backed by our ‘data for good’ principle, is to be at the forefront of this change, guiding, and contributing to this transformative journey.
Artificial Intelligence: The German Economy on the Cusp of Transformation
By Jochen Werne
1st October 2023, Düsseldorf
The “Experian 2023 Business Insights” report, released in September 2023, provides a revealing insight into the priorities of the global business community in the coming year. Particularly of interest to us in Germany is the insight into the transformative influence of Artificial Intelligence (AI) on areas such as analytics, risk assessment, and customer experience in the EMEA/APAC region.
Our German decision-makers are well aware of the pivotal role of AI in innovations. An encouraging finding: 60 percent of businesses in our country have already taken active steps to integrate AI into their processes.
However, the report also shows that not all executives in Germany are fully convinced of the benefits of using AI. The efficiency of AI in companies will determine how Germany stands as an economic location in an increasingly digital age. The transformation of raw data into meaningful insights and analyses will become a crucial competitive advantage for us.
It’s heartening to see that many of our international counterparts already recognise the benefits of AI. For more than half of the global companies, the productivity gains from AI already outweigh the initial costs.
One thing is clear: Our data infrastructure and the amount of data available will play a key role in the successful implementation of AI. Here, we as German businesses have some hurdles to overcome, especially regarding the availability of relevant data for critical business decisions.
In conclusion, I want to stress that, even with all the technology and data, we must never forget our ethical responsibility. AI must be employed in a transparent and responsible manner. The fact that already 61 percent of businesses in the EMEA/APAC region have a comprehensive AI risk management programme in place is promising.
The future is clear: businesses that properly harness AI will lead the competition. They’ll be able to leverage process efficiency and automation to unlock new growth opportunities.
For those who wish to read the full “Experian 2023 Business Insights Report”, you can find it here.
There’s a peculiar phenomenon that often goes unnoticed: we vividly remember the moments in our lives when we made pivotal decisions, but the lazy Sundays we spent lounging on the couch tend to blur into obscurity. Why is that? From the standpoint of psychology and neuroscience, active decision-making engages multiple brain regions, specifically the frontal cortex. This engagement imprints these moments deeply in our memory.
Decisions are the very essence of our existence. On a daily basis, we make around 35,000 decisions, from what to wear to how to react in crucial life situations. In the realms of politics and business, decisions are made amidst uncertainty. The quality and timeliness of these decisions often determine success or failure. The better we are at decision-making, the more successful we become.
However, decisions aren’t made in a vacuum. They are greatly influenced by our emotions, past experiences, and even biases. Let’s delve into game theory, a study that examines mathematical models of strategic interaction. This theory was so revolutionary that scientists like John Nash were awarded the Nobel Prize for their contributions. It showcases the intricacies of making decisions when multiple players are involved, each trying to maximize their own benefits. For instance, the “Prisoner’s Dilemma” is a classic example. It illustrates how two individuals, aiming to minimize their punishments, often don’t cooperate, even if it’s in their best interest. Their decision, influenced by a lack of trust and the inability to communicate, usually leads to a suboptimal outcome for both.
Another interesting lens through which to view decision-making is behavioural finance. This field has shown that people don’t always act rationally, and their decisions are swayed by psychological factors. The Dot-com Bubble of the late 1990s offers a poignant example. During this period, a frenzy around internet-based businesses led to skyrocketing stock prices, despite many of these companies having no solid profits or clear business plans. Overconfidence and herd behavior drove investors to pour money into these stocks, leading to massively inflated valuations. The bubble inevitably burst in the early 2000s, resulting in significant financial losses for countless investors. This incident underscores the dangers of letting emotions and biases overrule rational financial decision-making.
Given the complexities, decision-makers often seek a solid foundation for their choices. This is where data comes into play. But data is not just essential; it’s omnipresent. It’s estimated that 2.5 quintillion bytes of data are created every day. Like water, it’s everywhere. And just as water can flood a village if not channeled properly, unstructured data can overwhelm and mislead.
Take the banking sector, for instance. Banks use data to assess creditworthiness. In e-commerce, data-driven algorithms suggest products to consumers. Telecom industries utilize data to enhance customer experience and predict churn. The cornerstone of these industries is state-of-the-art data analytics capabilities paired with robust decision engines.
However, with the influx of data, it’s crucial to discern the essential from the redundant. Much like converting saltwater to drinking water requires precision and expertise, sifting through raw data to extract meaningful insights is the forte of data analysts. They refine data into actionable decision-making parameters, reducing uncertainty. And in business, reduced uncertainty translates to reduced risk and increased profitability.
To conclude, data is indeed akin to water. Left unchecked or misused, it can wreak havoc. But when used right, when structured, analyzed, and enriched, it becomes invaluable. This is the essence of using “Data for Good” – transforming the ubiquitous into the indispensable, guiding decision-makers toward better, more informed choices.


















 by Jochen Werne
by Jochen Werne






















 Author: Jochen Werne / 26.12.2023
Author: Jochen Werne / 26.12.2023