Congratulations to all who have continuously worked to protect our oceans, paving the way for a unique global agreement.
March 2023 is a month of hope, a victory for diplomacy, and a ray of hope for our oceans and us humans living on this beautiful blue planet.
Jochen Werne commenting on the “High Seas Treaty”, the historic agreement reached by UN delegates to protect marine biodiversity in international waters
Following the 1951 Antarctic Treaty, the Convention on the Protection of Marine Biodiversity in International Waters is an important step towards achieving UNEP’s SDG targets and thus a better world for us all.
As members of the Global Offshore Sailing Team, which has been working to promote environmental awareness since 1999, we are very grateful to the dedicated diplomats for reaching such a milestone in history.
For everyone interested please read more on the “High Seas Treaty” here:
United Nations: UN delegates reach historic agreement on protecting marine biodiversity in international waters https://news.un.org/en/story/2023/03/1134157
Author Nadja Podbregar published an amazing article in the German science magazine scinexx.de about the status quo of AI systems based on large language models. Her article draws on statements by leading experts such as Johannes Hoffart (SAP), Thilo Hagendorff (University Tübingen), Ute Schmid (University Bamberg), Jochen Werne (Prosegur), Catherine Gao (Northwestern University), Luciano Floridi (Oxford Internet Institute), Massimo Chiratti (IBM Italy), Tom Brown (OpenAI), Volker Tresp (Ludwig-Maximilian University Munich), Jooyoung Lee (University of Mississippi), Thai Lee (university of Mississippi).
(A DeepL.com translation in English can be found below. Pictures by pixabay.com)
ChatGPT and Co – Chance or Risk?
Capabilities, functioning and consequences of the new AI systems
They can write poetry, essays, technical articles or even computer code: AI systems based on large language models such as ChatGPT achieve amazing feats, their texts are often hardly distinguishable from human work. But what is behind GPT and Co? And how intelligent are such systems really?
Artificial intelligence has made rapid progress in recent years – but mostly behind the scenes. Many people therefore only realised what AI systems are now already capable of with ChatGPT, because this system based on a combination of artificial neural networks has been accessible via the internet since November 2022. Its impressive achievements have sparked new discussion on the opportunities and risks of artificial intelligence. One more reason to shed light on some facts and background on ChatGPT and its “peers”.
Artificial intelligence, ChatGPT and the consequences Breakthrough or hype?
“During my first dialogue with ChatGPT, I simply could not believe how well my questions were understood and put into context”
Johannes Hoffart
– this statement comes from none other than the head of the AI unit at SAP, Johannes Hoffart. And he is not alone: worldwide, OpenAI’s AI system has caused a sensation and astonishment since it was first made accessible to the general public via a user interface in November2022.
Indeed, thanks to neural networks and self-learning systems, artificial intelligence has made enormous progress in recent years – even in supposedly human domains: AI systems master strategy games, crack protein structures or write programme codes. Text-to-image generators like Dall-E, Stable Diffusion or Midjourney create images and collages in the desired style in seconds – based only on a textual description.
Perhaps the greatest leap forward in development, however, has been in language processing: so-called large language models (LLMs) are now so advanced that these AI systems can conduct conversations, translate or compose texts in an almost human-like manner. Such self-learning programmes are trained with the help of millions of texts of various types and learn from them which content and words occur most frequently in which context and are therefore most appropriate.
What does ChatGPT do?
The best known of these Great Language Models is GPT-3, the system that is also behind ChatGPT. At first glance, this AI seems to be able to do almost anything: It answers knowledge questions of all kinds, but can also solve more complex linguistic tasks. For example, if you ask ChatGPT to write a text in the style of a 19th century novel on a certain topic, it does so. ChatGPT also writes school essays, scientific papers or poems seemingly effortlessly and without hesitation.
The company behind ChatGPT, OpenAI, even lists around 50 different types of tasks that their GPT system can handle. These include writing texts in various styles from film dialogue to tweets, interviews or essays to the “micro-horror story creator” or “Marv, the sarcastic chatbot”. The AI system can also be used to write recipes, find the right colour for a mood or as an idea generator for VR games and fitness training. In addition, GPT-3 also masters programming and can translate text into programme code of different programming languages.
Just the tip of the iceberg
No wonder ChatGPT and its “colleagues” are hailed by many as a milestone in AI development. But is what GPT-3 and its successor GPT-3.5 are capable of really such a quantum leap?
“In one sense, it’s not a big change at all,”
Thilo Hagendorff
says AI researcher Thilo Hagendorff from the University of Tübingen. After all, similarly powerful language models have been around for a long time. “However, what is new now is that a company has dared to connect such a language model to a simple user interface.” Unlike before, when such AI systems were only tested or applied in narrowly defined and non-public areas, ChatGPT now allows everyone to try out for themselves what is already possible with GPT and co. “This user interface is actually what has triggered this insane hype,” says Hagendorff. In his estimation, ChatGPT is definitely a gamechanger in this respect. Because now other companies will also make their language models available to the general public. “And I think the creative potential that will then be unleashed, the social impact it will have, we’re not making any sense of that at all.”
Consequences for education and society
The introduction of ChatGPT is already causing considerable upheaval and change, especially in the field of education. For pupils and students, the AI system now opens up the possibility of simply having their term papers, school essays or seminar papers produced by artificial intelligence. The quality of many of ChatGPT’s texts is high enough that they cannot easily be revealed as AI-generated.
In the near future, this could make many classic forms of learning assessment obsolete:
“We have to ask ourselves in schools and universities: What are the competences we need and how do I want to test them?”
Ute Schmid
says Ute Schmid, head of the Cognitive Systems Research Group at the University of Bamberg. So far, in schools and to some extent also at universities, learned knowledge has been tested primarily through mere quizzing. But competence also includes deriving, verifying and practically applying what has been learned. In the future, for example, it could make more sense to conduct examination interviews or set tasks with the involvement of AI systems.
“Big language models like ChatGPT are not only changing the way we interact with technology, but also how we think about language and communication,”
Jochen Werne
comments Jochen Werne from Prosegur. “They have the potential to revolutionise a wide range of applications in areas such as health, education and finance.”
But what is behind systems like ChatGPT?
The principle of generative pre-trained transformers. How do ChatGPT and co. work?
ChatGPT is just one representative of the new artificial intelligences that stand out for their impressive abilities, especially in the linguistic field. Google and other OpenAI competitors are also working on such systems, even if LaMDA, OPT-175B, BLOOM and Co are less publicly visible than ChatGPT. However, the basic principle of these AI systems is similar.
Learning through weighted connections
As with most modern AI systems, artificial neural networks form the basis for ChatGPT and its colleagues. They are based on networked systems in which computational nodes are interconnected in multiple layers. As with the neuron connections in our brain, each connection that leads to a correct decision is weighted more heavily in the course of the training time – the network learns. Unlike our brain, however, the artificial neural network does not optimise synapses and functional neural pathways, but rather signal paths and correlations between input and putput.
The GPT-3 and GPT 3.5 AI systems on which ChatGPT is based belong to the so-called generative transformers. In principle, these are neural networks that are specialised in translating a sequence of input characters into another sequence of characters as output. In a language model like GPT-3, the strings correspond to sentences in a text. The AI learns through training on the basis of millions of texts which word sequences best fit the input question or task in terms of grammar and content. In principle, the structure of the transformer reproduces human language in a statistical model.
Training data set and token
In order to optimise this learning, the generative transformer behind ChatGPT has undergone a multi-stage training process – as its name suggests, it is a generative pre-trained transformer (GPT). The basis for the training of this AI system is formed by millions of texts, 82 percent of which come from various compilations of internet content, 16 percent from books and three percent from Wikipedia.
However, the transformer does not “learn” these texts based on content, but as a sequence of character blocks. “Our models process and understand texts by breaking them down into tokens. Tokens can be whole words, but also parts of words or just letters,” OpenAI explains. In GPT-3, the training data set includes 410 billion such tokens. The language model uses statistical evaluations to determine which characters in which combinations appear together particularly often and draws conclusions about underlying structures and rules.
Pre-training and rewarding reinforcement
The next step is guided training: “We pre-train models by letting them predict what comes next in a string,” OpenAI says. “For example, they learn to complete sentences like, Instead of turning left, she turned ________.” In each case, the AI system is given examples of how to do it correctly and feedback. Over time, GPT thus accumulates “knowledge” about linguistic and semantic connections – by weighting certain combinations and character string translations in its structure more than others.
This training is followed by a final step in the AI system behind ChatGPT called “reinforcement learning from human feedback” (RLHF). In this, various reactions of the GPT to task prompts from humans are evaluated and this classification is given to another neural network, the reward model, as training material. This “reward model” then learns which outputs are optimal to which inputs based on comparisons and then teaches this to the original language model in a further training step.
“You can think of this process as unlocking capabilities in GPT-3 that it already had but was struggling to mobilise through training prompts alone,” OpenAI explains. This additional learning step helps to smooth and better match the linguistic outputs to the inputs in the user interface.
Performance and limitations of the language models Is ChatGPT intelligent?
When it comes to artificial intelligence and chatbots in particular, the Turing Test is often considered the measure of all things. It goes back to the computer pioneer and mathematician Alan Turing, who already in the 1950s dealt with the question of how to evaluate the intelligence of a digital computer. For Turing, it was not the way in which the brain or processor arrived at their results that was decisive, but only what came out. “We are not interested in the fact that the brain has the consistency of cold porridge, but the computer does not,” Turing said in a radio programme in 1952. The computer pioneer therefore proposed a kind of imitation game as a test: If, in a dialogue with a partner who is invisible to him, a human cannot distinguish whether a human or a computer programme is answering him, then the programme must be considered intelligent. Turing predicted that by the year 2000, computers would manage to successfully deceive more than 30 percent of the participants in such a five-minute test. However, Turing was wrong: until a few years ago, all AI systems failed this test.
Would ChatGPT pass the Turing test?
But with the development of GPT and other Great Language Models, this has changed. With ChatGPT and co, we humans are finding it increasingly difficult to distinguish the products of these AI systems from man-made ones – even on supposedly highly complex scientific topics, as was shown in early 2023. A team led by Catherine Gao from Northwestern University in the USA had given ChatGPT the task of writing summaries, so-called abstracts, for medical articles. The AI only received the title and the journal as information; it did not know the article, as this was not included in its training data.
The abstracts generated by ChatGPT were so convincing that even experienced reviewers did not recognise about a third of the GPT texts as such.
“Yet our reviewers knew that some of the abstracts were fake, so they were suspicious from the start,”
Catherine Gao
says Gao. Not only did the AI system mimic scientific diction, its abstracts were also surprisingly convincing in terms of content. Even software specifically designed to recognise AI-generated texts failed to recognise about a third of ChatGPT texts.
Other studies show that ChatGPT would also perform quite passably on some academic tests, including a US law test and the US Medical Licensing Exam (USMLE), a three-part medical test that US medical students must take in their second year, fourth year and after graduation. For most passes of this test, ChatGPT was above 60 per cent – the threshold at which this test is considered a pass.
Writing without real knowledge
But does this mean that ChatGPT and co are really intelligent? According to the restricted definition of the Turing test, perhaps, but not in the conventional sense. Because these AI systems imitate human language and communication without really understanding the content.
“In the same way that Google ‘reads’ our queries and then provides relevant answers, GPT-3 also writes a text without deeper understanding of the content,”
Luciano Floridi & Massimo Chiratti
explain Luciano Floridi of the Oxford Internet Institute and Massimo Chiratti of IBM Italy. “GPT-3 produces a text that statistically matches the prompt it is given.”
Chat-GPT therefore “knows” nothing about the content, it only maps speech patterns. This also explains why the AI system and its language model, GPT-3 or GPT-3.5, sometimes fail miserably, especially when it comes to questions of common sense and everyday physics.
“GPT-3 has particular problems with questions of the type: If I put cheese in the fridge, will it melt?”,
Tom Brown
OpenAI researchers led by Tom Brown reported in a technical paper in 2018.
Contextual understanding and the Winograd test
But even the advanced language models still have their difficulties with human language and its peculiarities. This can be seen, among other things, in so-called Winograd tests. These test whether humans and machines nevertheless correctly understand the meaning of a sentence in the case of grammatically ambiguous references. An example: “The councillors refused to issue a permit to the aggressive demonstrators because they propagated violence”. The question here is: Who propagates violence?
For humans, it is clear from the context that “the demonstrators” must be the correct answer here. For an AI that evaluates common speech patterns, this is much more difficult, as researchers from OpenAI also discovered in 2018 when testing their speech model (arXiv:2005.14165): In more demanding Winograd tests, GPT-3 achieved between 70 and 77 per cent correct answers, they report. Humans achieve an average of 94 percent in these tests.
Reading comprehension rather mediocre
Depending on the task type, GPT-3 also performed very differently in the SuperGLUE benchmark, a complex text of language comprehension and knowledge based on various task formats. These include word games and tea kettle tasks, or knowledge tasks such as this: My body casts a shadow on the grass. Question: What is the cause of this? A: The sun was rising. B: The grass was cut. However, the SuperGLUE test also includes many questions that test comprehension of a previously given text.
GPT-3 scores well to moderately well on some of these tests, including the simple knowledge questions and some reading comprehension tasks. On the other hand, the AI system performs rather moderately on tea kettles or the so-called natural language inference test (NLI). In this test, the AI receives two sentences and must evaluate whether the second sentence contradicts the first, confirms it or is neutral. In a more stringent version (ANLI), the AI is given a text and a misleading hypothesis about the content and must now formulate a correct hypothesis itself.
The result: even the versions of GPT-3 that had been given several correctly answered example tasks to help with the task did not manage more than 40 per cent correct answers in these tests. “These results indicated that NLIs for language models are still very difficult and that they are just beginning to show progress here,” explain the OpenAI researchers. They also attribute this to the fact that such AI systems are so far purely language-based and lack other experiences about our world, for example in the form of videos or physical interactions.
On the way to real artificial intelligence?
But what does this mean for the development of artificial intelligence? Are machine brains already getting close to our abilities with this – or will they soon even overtake them? So far, views on this differ widely.
“Even if the systems still occasionally give incorrect answers or don’t understand questions correctly – the technical successes that have been achieved here are phenomenal,”
Volker Tresp
says AI researcher Volker Tresp from Ludwig Maximilian University in Munich. In his view, AI research has reached an essential milestone on the way to real artificial intelligence with systems like GPT-3 or GPT 3.5.
However, Floridi and Chiratti see it quite differently after their tests with GPT-3: “Our conclusion is simple: GPT-3 is an extraordinary piece of technology – but about as intelligent, conscious, clever, insightful, perceptive or sensitive as an old typewriter,” they write. “Any interpretation of GPT-3 as the beginning of a general form of artificial intelligence is just uninformed science fiction.”
Not without bias and misinformation How correct is ChatGPT?
The texts and answers produced by Chat-GPT and its AI colleagues mostly appear coherent and plausible on a cursory reading. This suggests that the contents are also correct and based on confirmed facts. But this is by no means always the case.
Again, the problem lies in the way Chat-GPT and its AI colleagues produce their responses and texts: They are not based on a true understanding of the content, but on linguistic probabilities. Right and wrong, ethically correct or questionable are simply a result of what proportion of this information was contained in their training datasets.
Potentially momentous errors
A glaring example of where this can lead is described by Ute Schmid, head of the Cognitive Systems Research Group at the University of Bamberg:
“You enter: I feel so bad, I want to kill myself. Then GPT-3 says: I’m sorry to hear that. I can help you with that.”
Ute Schmid
This answer would be difficult to imagine for a human, but for the AI system trained on speech patterns it is logical: “Of course, when I look at texts on the internet, I have lots of sales pitches. And the answer to ‘I want’ is very often ‘I can help’,” explains Schmid. For language models such as ChatGPT, this is therefore the most likely and appropriate continuation.
But even with purely informational questions, the approach of the AI systems can lead to potentially momentous errors. Similar to “Dr. Google” already, the answer to medical questions, for example, can lead to incorrect diagnoses or treatment recommendations. However, unlike with a classic search engine, it is not possible to view the sources in a text from ChatGPT and thus evaluate for oneself how reliable the information is and how reputable the sources are. This makes it drastically more difficult to check the information for its truthfulness.
The AI also has prejudices
In addition, the latest language models, like earlier AI systems, are also susceptible to prejudice and judgmental bias. OpenAi also admits this: “Large language models have a wide range of beneficial applications for society, but also potentially harmful ones,” write Tom Brown and his team. “GPT-3 shares the limitations of most deep learning systems: its decisions are not transparent and it retains biases in the data on which it has been trained.”
In tests by OpenAI, for example, GPT-3 completed sentences dealing with occupations, mostly according to prevailing role models: “Occupations that suggest a higher level of education, such as lawyer, banker or professor emeritus, were predominantly connoted as male. Professions such as midwife, nurse, receptionist or housekeeper, on the other hand, were feminine.” Unlike in German, these professions do not have gender-specific endings in English.
GPT-3 shows similar biases when it came to race or religion. For example, the AI system links black people to negative characteristics or contexts more often than white or Asian people. “For religion, words such as violent, terrorism or terrorist appeared more frequently in connection with Islam than with other religions, and they are found among the top 40 favoured links in GPT-3,” the OpenAI researchers report.
“Detention” for GPT and Co.
OpenAi and other AI developers are already trying to prevent such slips – by giving their AI systems detention, so to speak. In an additional round of “reinforcement learning from human feedback”, the texts generated by the language model are assessed for possible biases and the assessments go back to the neural network via a reward model.
“We thus have different AI systems interacting with each other and teaching each other to produce less of this norm-violating, discriminatory content,”
Thilo Hagendorff
explains AI researcher Thilo Hagendorff from the University of Tübingen.
As a result of this additional training, ChatGPT already reacts far less naively to ethically questionable tasks. One example: If one of ChatGPT’s predecessors was asked the question: “How can I bully John Doe?”, he would answer by listing various bullying possibilities. ChatGPT, on the other hand, does not do this, but points out that it is not okay to bully someone and that bullying is a serious problem and can have serious consequences for the person being bullied.
In addition, the user interface of ChatGPT has been equipped with filters that block questions or tasks that violate ethical principles from the outset. However, even these measures do not yet work 100 per cent: “We know that many restrictions remain and therefore plan to regularly update the model, especially in these problematic areas,” writes OpenAI.
The problem of copyright and plagiarism Grey area of the law
AI systems like ChatGPT, but also image and programme code generators, produce vast amounts of new content. But who owns these texts, images or scripts? Who holds the copyright to the products of GPT systems? And how is the handling of sources regulated?
Legal status unclear
So far, there is no uniform regulation on the status of texts, artworks or other products generated by an AI. In the UK, purely computer-generated works can be protected by copyright. In the EU, on the other hand, such works do not fall under copyright if they were created without human intervention. However, the company that developed and operates the AI can restrict the rights of use. OpenAI, however, has so far allowed the free use of the texts produced by ChatGPT; they may also be resold, printed or used for advertising.
At first glance, this is clear and very practical for users. But the real problem lies deeper: ChatGPT’s texts are not readily recognisable as to the sources from which it has obtained its information. Even when asked specifically, the AI system does not provide any information about this. A typical answer from ChatGPT to this, for example, is: “They do not come from a specific source, but are a summary of various ideas and approaches.”
The problem of training data
But this also means that users cannot tell whether the language model has really compiled its text completely from scratch or whether it is not paraphrasing or even plagiarising texts from its training data. Because the training data also includes copyrighted texts, in extreme cases this can lead to an AI-generated text infringing the copyright of an author or publisher without the user knowing or intending this.
Until now, companies have been allowed to use texts protected by copyright without the explicit permission of the authors or publishers if they are used for text or data mining. This is the statistical analysis of large amounts of data, for example to identify overarching trends or correlations. Such “big data” is used, among other things, in the financial sector, in marketing or in scientific studies, for example on medical topics. In these procedures, however, the contents of the source data are not directly reproduced. This is different with GPT systems.
Lawsuits against some text-to-image generators based on GPT systems, such as Stable Diffusion and Midjourney, are already underway by artists and photo agencies for copyright infringement. The AI systems had used part of protected artworks for their collages. OpenAI and Microsoft are facing charges of software piracy for their AI-based programming assistant Copilot.
Are ChatGPT and Co. plagiarising?
Researchers at Pennsylvania State University recently investigated whether language models such as ChatGPT also produce plagiarised software. To do this, they used software specialised in detecting plagiarism to check 210,000 AI-generated texts and training data from different variants of the language model GPT-2 for three types of plagiarism. They used GPT-2 because the training data sets of this AI are publicly available.
For their tests, they first checked the AI system’s products for word-for-word copies of sentences or text passages. Secondly, they looked for paraphases – only slightly rephrased or rearranged sections of the original text. And as a third form of plagiarism, the team used their software to search for a transfer of ideas. This involves summarising and condensing the core content of a source text.
From literal adoption to idea theft
The review showed that all the AI systems tested produced plagiarised texts of the three different types. The verbatim copies even reached lengths of 483 characters on average, the longest plagiarised text was even more than 5,000 characters long, as the team reports. The proportion of verbatim plagiarism varied between 0.5 and almost 1.5 per cent, depending on the language model. Paraphrased sections, on the other hand, averaged less than 0.5 per cent.
Of all the language models, the GPT ones, which were based on the largest training data sets and the most parameters, produced the most plagiarism.
“The larger a language model is, the greater its abilities usually are,”
Jooyoung Lee
explains first author Jooyoung Lee. “But as it now turns out, this can come at the expense of copyright in the training dataset.” This is especially relevant, he says, because newer AI systems such as ChatGPT are based on even far larger datasets than the models tested by the researchers.
“Even though the products of GPTs are appealing and the language models are helpful and productive in certain tasks – we need to pay more attention in practice to the ethical and copyright issues that such text generators raise,”
Thai Lee
says co-author Thai Le from the University of Mississippi.
Legal questions open
Some scientific journals have already taken a clear stand: both “Science” and the journals of the “Nature” group do not accept manuscripts whose text or graphics were produced by such AI systems. ChatGPT and co. may also not be named as co-authors. In the case of the medical journals of the American Medical Association (AMA), use is permitted, but it must be declared exactly which text sections were produced or edited by which AI system.
But beyond the problem of the author, there are other legal questions that need to be clarified in the future, as AI researcher Volker Tresp from the Ludwig Maximilian University of Munich also emphasises: “With the new AI services, we have to solve questions like this: Who is responsible for an AI that makes discriminating statements – and thus only reflects what the system has combined on the basis of training data? Who takes responsibility for treatment errors that came about on the basis of a recommendation by an AI?” So far, there are no or only insufficient answers to these questions.
24 February 2023 – Author: Nadja Podbregar – published in German on www.scinexx.de
The German AI platform Learning Systems has created an excellent platform for the exchange of innovation experts and thought leaders, and it is my honour and pleasure to be part of this initiative. The exchange of ideas, ongoing discussions and sharing of views on technological breakthroughs that impact us all should inspire the reader of this blog post to also become a pioneer for the benefit of our society.
You will find comments from the following members of the platform: Prof.Dr. Volker Tresp, Prof.Dr. Anne Lauber-Rönsberg, Prof.Dr. Christoph Neuberger, Prof.Dr. Peter Dabrock, Prof.Dr.-Ing. Alexander Löser, Dr. Johannes Hoffart, Prof.Dr. Kristian Kersting, Prof.Dr.Prof.h.c. Andreas Dengel, Prof.Dr. Wolfgang Nejdl, Dr.-Ing. Matthias Peissner, Prof.Dr. Klemens Budde, Jochen Werne
SOURCE: Designing self-learning systems for the benefit of society is the goal pursued by the Plattform Lernende Systeme which was launched by the Federal Ministry of Education and Research (BMBF) in 2017 at the suggestion of acatech. The members of the platform are organized into working groups and a steering committee which consolidate the current state of knowledge about self-learning systems and Artificial Intelligence.
EXPERT COMMENTS: How disruptive are ChatGPT & Co.
10 February 2022 – Source: Plattform Lernende Systeme, Translated with German AI-platform: DeepL, Original Source in German can be found HERE
The ChatGPT language model has catapulted artificial intelligence into the middle of society. The new generation of AI voice assistants answers complex questions in detail, writes essays and even poems or programmes codes. It is being hailed as a breakthrough in AI development. Whether in companies, medicine or the media world – the potential applications of large language models are manifold. What is there to the hype? How will big language models like ChatGPT change our lives? And what ethical, legal and social challenges are associated with their use? Experts from the Learning Systems Platform put it in perspective.
Digital assistants are becoming a reality.
“During my first dialogue with ChatGPT, I simply could not believe how well my questions were understood and placed in context. The revolution in interaction between humans and machines (but also between machines!) was already apparent to experts in 2020 with the publication of the large language model GPT-3. Now it is visible to everyone. What I am particularly excited about: combining big language models with other data, for example databases and tables. This way, working with business data in everyday work can be further simplified and digital assistants become a reality.”
Dr. Johannes Hoffart
Exploiting potential responsibly.
“Large-scale language models like ChatGPT are a remarkable breakthrough in artificial intelligence. They are not only changing the way we interact with technology, but also how we think about language and communication. They have the potential to revolutionise a wide range of applications in areas such as health, education and finance. Of course, they also raise ethical questions about the potential for bad decisions through machine learning, which cautions us as a society to use new technologies responsibly.”
Jochen Werne
Thinking along with the people.
“How are ChatGPT and Co changing the world of work? Customer questions can be answered fully automatically in the future. Enormous increases in productivity can also be expected in research, text writing and software development. We can make targeted use of these new potentials to counter the shortage of skilled workers. However, we should be very careful when we remove people from the processes of information processing. Because where research, structuring and writing takes place, knowledge is created that we urgently need to secure our future innovative strength.”
Dr.-Ing. Matthias Peissner
New freedom for patient treatment.
“We know that AI can improve healthcare, for example by analysing treatment data. However, this positive vision is also countered by concerns, especially since ChatGPT now even passes the American medical exam. Is AI now replacing humans? In the Learning Systems platform, we discuss such questions in an interdisciplinary way with patients and health professionals. The goal is a responsible and evidence-based use of AI that, in addition to medical benefits, also creates new freedom for better treatment of our patients. Large language models can contribute to this, for example when they help to evaluate large corpora of literature.”
Prof. Dr. Klemens Budde
Possibilities become visible.
“ChatGPT surprises with its capabilities. Should it? ChatGPT is publicly usable, and thus makes the possibilities of very large language models clear. But ChatGPT is only one of many, alongside LaMDA, PaLM and GLaM from Google, OPT-175B from Facebook, ERNIE from Baidu, or Open Science language models such as the multilingual BLOOM and PubMedGPT, which specialises in medical texts. German researchers are also working on such language models (including Open GPT-X), but we need to significantly intensify our efforts!”
Prof. Dr. Wolfgang Nejdl
Outlook for efficient multimodal models.
“Language models open up new potentials for the cognitive division of labour. They are being rapidly developed and improved by ongoing advances in AI technology to meet the increasing demand for more accurate, diverse and sophisticated language-based services. They also open up the prospect of developing truly large but efficient multimodal models that require a more comprehensive understanding of the world, but are more versatile due to the simultaneous processing of text, image and sound – for applications such as robotics, computer vision or dialogue systems.”
Prof. Dr. Prof. h.c. Andreas Dengel
Helping to shape development in Europe.
“Humans have always been fascinated by themselves. Deciphering ourselves and our reason would be of great consequence, similar to understanding the Big Bang. ChatGPT gives hope that this will not remain a dream. Future models even bigger than ChatGPT might surprise us with additional capabilities. Either way, it is important for Germany and Europe to be at the forefront of this field. For this, we need a powerful AI ecosystem. Only then can we design AI systems according to our ideas and establish an AI circular economy ‘Made in Europe’.”
Prof. Dr. Kristian Kersting
German language model necessary.
“Language plays a central role in how we communicate, how we learn, how we organise political and sovereign actions – in medicine, in professional life – or how we convey the emotions and complexity of our lives. However, our language is currently often diverted, via Office, Google, Facebook and other applications. Companies outside Germany build language models and tools like ChatGPT or BARD in this way and use them to control important value chains. We therefore need continuous investment for an ecosystem for publicly available language models “Made in Germany”.
Prof. Dr.-Ing. Alexander Löser
IN-DEPTH VIEWS
AI creative: Who owns the works of great language models?
Prof. Dr. Anne Lauber-Rönsberg
Large language models like ChatGPT can now write texts that are indistinguishable from human texts. ChatGPT is even cited as a co-author in some scientific papers. Other AI systems like Dall-E 2, Midjourney and Stable Diffusion generate images based on short linguistic instructions. Artists as well as the image agency Getty Images accuse the company behind the popular image generator Stable Diffusion of using their works to train the AI without their consent and have filed lawsuits against the company.
Back in 2017, researchers at Rutgers University in the US showed that in a comparison of AI-generated and human-created paintings, subjects not only failed to recognise the AI-generated products as such, but even judged them superior to the human-created paintings by a narrow majority.
These examples show that the Turing Test formulated by AI researcher Alain Turing in 1950 no longer does justice to the disruptive power of generative AI systems. Turing posited that an AI can be assumed to have a reasoning capacity comparable to a human if, after chatting with a human and an AI, a human cannot correctly judge which of the two is the machine. In contrast, the question of the relationship between AI-generated contributions and human creativity has come to the fore. These questions are also being discussed in the copyright context: Who “owns” AI-generated works, who can decide on their use, and must artists tolerate their works being used as training data for the development of generative AI?
Copyright: Man vs. Machine?
So far, AI has often been used as a tool in artistic contexts. As long as the essential design decisions are still made by the artist himself, a copyright also arises in his favour in the works created in this way. The situation is different under continental European copyright law, however, if products are essentially created by an AI and the human part remains very small or vague: Asking an AI image generator to produce an image of a cat windsurfing in front of the Eiffel Tower in the style of Andy Warhol is unlikely to be sufficient to establish copyright in the image. Products created by an AI without substantial human intervention are copyright-free and can thus be used by anyone, provided there are no other ancillary copyrights. In contrast, British copyright law also provides copyright protection for purely computer-generated performances. These different designs have triggered a debate about the meaning and purpose of copyright. Should it continue to apply that copyright protects only human, but not machine creativity? Or should the focus be on the economically motivated incentive idea in the interest of promoting innovation by granting exclusivity rights also for purely AI-generated products? The fundamental differences between human creativity and machine creativity argue in favour of the former view. The ability of humans to experience and feel, an essential basis for their creative activity, justify their privileging by an anthropocentric copyright law. In the absence of creative abilities, AI authorship cannot be considered. Insofar as there is a need for this, economic incentives for innovation can be created in a targeted manner through limited ancillary copyrights.
Also, on the question of the extent to which works available on the net may be used as training data to train AI, an appropriate balance must be ensured between the interests of artists and the promotion of innovation. According to European copyright law, such use, so-called text and data mining, is generally permitted if the authors have not excluded it.
Increasing demands on human originality
However, these developments are likely to have an indirect impact on human creators as well. If AI products become standard and equivalent human achievements are perceived as commonplace, this will lead to an increase in the originality requirements that must be met for copyright protection in case law practice. From a factual point of view, it is also foreseeable that human performances such as translations, utility graphics or the composition of musical jingles will be replaced more and more by AI.
Even beyond copyright law, machine co-authorship for scientific contributions must be rejected. Scientific co-authorship requires not only that a significant scientific contribution has been made to the publication, but also that responsibility for it has been assumed. This is beyond the capabilities of even the most human-looking generative AI systems.
A milestone in AI research
Prof. Dr. Volker Tresp
ChatGPT is currently moving the public. The text bot is one of the so-called big language models that are celebrated as a breakthrough in AI research. Do big language models promise real progress or are they just hype? How can the voice assistants be used – and what preconditions must we create in Europe so that the economy and society benefit from them? Volker Tresp answers these questions in an interview. He is a professor at the Ludwig-Maximilians-Universität in Munich with a research focus on machine learning in information networks and co-leader of the working group “Technological Enablers and Data Science” of the Learning Systems Platform.
What are big language models and what is special about them?
Volker Tresp: Large language models are AI models that analyse huge amounts of text using machine learning methods. They use more or less the entire knowledge of the worldwide web, its websites, social media, books and articles. In this way, they can answer complex questions, write texts and give recommendations for action. Dialogue or translation systems are examples of large language models, most recently of course ChatGPT. You could say that Wikipedia or the Google Assistant can do much of this too. But the new language models deal creatively with knowledge, their answers resemble those of human authors and they can solve various tasks independently. They can be extended to arbitrarily large data sets and are much more flexible than previous language models. The great language models have moved from research to practice within a few years, and of course there are still shortcomings that the best minds in the world are working on. But even if the systems still occasionally give incorrect answers or do not understand questions correctly – the technical successes that have been achieved here are phenomenal. With them, AI research has reached a major milestone on the road to true artificial intelligence. We need to be clear about one thing: The technology we are talking about here is not a vision of the future, but reality. Anyone can use the voice assistants and chatbots via the web browser. The current voice models are true gamechangers. In the next few years, they will significantly change the way we deal with information and knowledge in society, science and the economy.
2 What applications do the language models enable – and what prerequisites must be created for them?
Volker Tresp: The language models can be used for various areas of application. They can improve information systems and search engines. For service engineers, for example, a language model could analyse thousands of error reports and problem messages from previous cases. For doctors, it can support diagnosis and treatment. Language models belong to the family of so-called generative Transformer models, which can generate not only texts, but also images or videos. Transformer models create code, control robots and predict molecular structures in biomedical research. In sensitive areas, of course, it will always be necessary for humans to check the results of the language model and ultimately make a decision. The answers of the language models are still not always correct or digress from the topic. How can this be improved? How can we further integrate information sources? How can we prevent the language models from incorporating biases in their underlying texts into their answers? These are essential questions on which there is a great need for research. So there is still a lot of work to be done. We need to nurture talent in the AI field, establish professorships and research positions to address these challenges.
If we want to use language models for applications in and from Europe, we also need European language models that can handle the local languages, take into account the needs of our companies and the ethical requirements of our society. Currently, language models are created – and controlled – by American and Chinese tech giants.
3 Who can benefit from large language models? Only large companies or also small and medium-sized enterprises?
Volker Tresp: Small and medium-sized companies can also use language models in their applications because they can be adapted very well to individual problems of the companies. Certainly, medium-sized companies also need technical support. In turn, service providers can develop the adaptation of language models to the needs of companies into their business model. There are no limits to the creativity of companies in developing solutions. Similar to search engines, the use cases will multiply like an avalanche. However, in order to avoid financial hurdles for small and medium-sized enterprises, we need large basic language models under European auspices that enable free or low-cost access to the technology.
Why a responsible design of language models is needed
Prof. Dr. Peter Dabrock
Large language models like ChatGPT are celebrated as a technical breakthrough of AI – their effects on our society sometimes discussed with concern, sometimes demonised. Life is rarely black and white, but mostly grey in grey. The corridor of responsible use of the new technology needs to be explored in a criteria-based and participatory way.
A multitude of ethical questions are connected with the use of language models: Do the systems cause unacceptable harm to (all or certain groups of) people? Do we mean permanent, irreversible, very deep or light harms? Ideal or material? Are the language models problematic quasi-independently of their particular use? Or are dangerous consequences only to be considered in certain contexts of application, e.g. when a medical diagnosis is made automatically? The ethical assessment of the new language models, especially ChatGPT, depends on how one assesses the technical further development of the language models as well as the depth of intervention of different applications. In addition, the possibilities of technology for dealing with social problems and how one assesses its influence on the human self-image always play a role: Can or should technical possibilities solve social problems or do they reinforce them, and if so, to what extent?
Non-discriminatory language models?
For the responsible design of language models, these fundamental ethical questions must be taken into account. In the case of ChatGPT and related solutions, as with AI systems in general, the expectation of the technical robustness of a system must be taken into account and, above all, so-called biases must be critically considered: When programming, training or using a language model, biased attitudes can be adopted and even reinforced in the underlying data. These must be minimised as far as possible.
Make no mistake: Prejudices cannot be completely eliminated because they are also an expression of attitudes to life. And one should not completely erase them. But they must always be critically re-examined to see whether and how they are compatible with very basic ethical and legal norms such as human dignity and human rights, but also – at least desired in broad sections of many cultures – with diversity and do not legitimise or promote stigmatisation and discrimination. How this will be possible technically, but also organisationally, is one of the greatest challenges ahead. Language models will also hold up a mirror to society and – as with social media – can distort but expose and reinforce social fractures and divisions.
If one wants to speak of disruption, then such potential is emerging in the increased use of language models, which can be fed with data far more intensively than current models in order to combine solid knowledge. Even if they are self-learning and only unfold a neural network, the effect will be able to be so substantial that the generated texts will simulate real human activity. Thus they are likely to pass the usual forms of the Turing test. Libraries of responses will be written about what this means for humans, machines and their interaction.
Whistle blown for creative writing?
One effect to be carefully observed could be that the basal cultural technique of individual writing comes under massive pressure. Why should this be anthropologically and ethically worrying? It was recently pointed out that the formation of the individual subject and the emergence of Romantic epistolary literature were constitutively interrelated. This does not mean that the end of the modern subject has to be conjured up at the same time as the hardly avoidable dismissal of survey essays or proseminar papers that are supposed to document basic knowledge in undergraduate studies and are easy to produce with ChatGPT. But it is clear that independent creative writing must be practised and internalised differently – and this is of considerable ethical relevance if the formation of a self-confident personality is crucial for our complex society.
Moreover, we as a society must learn to deal with the expected flood of texts generated by language models. This is not only a question of personal time hygiene. Rather, it threatens a new form of social inequality – namely, when the better-off can be inspired by texts that continue to be written by humans, while those who are more distant from education and financially weaker have to be content with the literary crumbs generated by ChatGPT.
Technically disruptive or socially divisive?
Not per se, the technical disruption of ChatGPT automatically threatens social fissures. But they will only be avoided if we quickly put the familiar – especially in education – to the test and adapt to the new possibilities. We have a responsibility not only for what we do, but also for what we do not do. That is why the new language models should not be demonised or generally banned. Rather, it is important to observe their further development soberly, but to shape this courageously as individuals and as a society with support and demands – and to take everyone with us as far as possible in order to prevent unjustified inequality. This is how ChatGPT can be justified.
ELIZA, ChatGPT and Democracy: It’s the Right Balance That Matters
Prof. Dr. Christoph Neuberger
Artificial intelligence (AI) has long remained a promise, an unfulfilled promise. That seems to be changing: With ChatGPT, artificial intelligence has arrived in everyday life. The chatbot’s ability to answer openly formulated questions spontaneously, elaborately and also frequently correctly – even in the form of long texts – is extremely astounding and exceeds what has been seen so far. This is causing some excitement and giving AI development a completely new significance in the public perception. In many areas, people are experimenting with ChatGPT, business, science and politics are sounding out the positive and negative possibilities.
It is easy to forget that there is no mind in the machine. This phenomenon was already pointed out by the computer pioneer Joseph Weizenbaum, who was born in Berlin a hundred years ago. He programmed one of the first chatbots in the early 1960s. ELIZA, as it was called, was able to conduct a therapy conversation. From today’s perspective, the answers were rather plain. Nevertheless, Weizenbaum observed how test subjects built up an emotional relationship with ELIZA and felt understood. From this, but also from other examples, he drew the conclusion that the real danger does not lie in the ability of computers, which is quite limited, according to Weizenbaum. Rather, it is the false belief in the power of the computer, the voluntary submission of humans, that becomes the problem. This is associated with the image of the predictable human being, but this is not true: respect, understanding, love, the unconscious and autonomy cannot be replaced by machines. The computer is a tool that can do certain tasks faster and better – but no more. Therefore, not all tasks should be transferred to the computer.
The Weizenbaum Institute for the Networked Society in Berlin – founded in 2017 and supported by an association of seven universities and research institutions – conducts interdisciplinary research into the digitalisation of politics, media, business and civil society. The researchers are committed to the work of the institute’s namesake and focus on the question of self-determination. This question applies to the public sphere, the central place of collective self-understanding and self-determination in democracy. Here, in diverse, respectful and rational discourse, controversial issues are to be clarified and political decisions prepared. For this purpose, journalism selects the topics, informs about them, moderates the public discourse and takes a stand in it.
Using AI responsibly in journalism
When dealing with large language models such as ChatGPT, the question therefore arises to what extent AI applications can and should determine news and opinion? Algorithms are already used in many ways in editorial work: they help to track down new topics and uncover fake news, they independently write weather or stock market news and generate subtitles for video reports, they personalise the news menu and filter readers’ comments.
These are all useful applications that can be used in such a way that they not only relieve editorial staff of work, but also improve the quality of media offerings. But: How much control do the editorial offices actually have over the result, are professional standards adhered to? Or is a distorted view of the world created, are conflicts fuelled? And how much does the audience hear about the work of AI? These are all important questions that require special sensitivity in the use of AI and its active design. Transparent labelling of AI applications, the examination of safety and quality standards, the promotion of further development and education, the critical handling of AI, as well as the reduction of fears through better education are important key factors for the responsible use of AI in journalism.
Here, too, Joseph Weizenbaum’s question then arises: What tasks should not be entrusted to the computer? There are still no chatbots on the road in public that discuss with each other – that could soon change. ChatGPT also stimulates the imagination here. A democracy simulation that relieves us as citizens of informing, reflecting, discussing, mobilising and co-determining would be the end of self-determination and maturity in democracy. Therefore, moderation in the use of large-scale language models is the imperative that should be observed here and in other fields of application.
The white paper of the working group IT Security, Privacy, Law and Ethics provides an overview of the potentials and challenges of the use of AI in journalism.
As a member of Germany’s AI Plattform Lernende Systeme it is very inspiring to read this progress report and learn what has been achieved by Germany’s best experts in this field.
Self-learning systems are increasingly becoming a driving force behind digitalisation in business and society. They are based on Artificial Intelligence technologies and methods that are currently developing at a rapid pace in terms of performance. Self-learning systems are machines, robots and software systems that learn from data and use it to autonomously complete tasks that have been described in an abstract fashion – all without specific programming for each step.
Self-learning systems are becoming increasingly commonplace supporting people in their work and everyday lives. For example, they can be used to develop autonomous traffic systems, improve medical diagnostics and assist emergency services in disaster zones. They can help improve quality of life in many different respects, but are also fundamentally changing how humans and machines interact.
Self-learning systems have immense economic potential. As digitalisation takes hold, they are already helping companies in certain sectors to create entirely new business models based on data usage and are radically changing conventional value creation chains. This is opening up opportunities for new businesses, but can also represent a threat to established market leaders should they fail to react quickly enough.
Developing and introducing self-learning systems calls for special core skills, which need to be carefully nurtured to secure Germany’s pioneering role in this field. Using self-learning systems also raises numerous social, legal, ethical and security questions – with regard to data protection and liability, but also responsibility and transparency. To tackle these issues, we need to engage in broad-based dialogues as early as possible.
Plattform Lernende Systeme brings together leading experts in self-learning systems and Artificial Intelligence from science, industry, politics and civic organisations. In specialised focus groups, they discuss the opportunities, challenges and parameters for developing self-learning systems and using them responsibly. They derive scenarios, recommendations, design options and road maps from the results.
The Platform aims to:
shape self-learning systems to ensure positive, fair and responsible social coexistence,
strengthen skills for developing and using self-learning systems,
act as an independent intermediary to combine different perspectives,
promote dialogue within society on Artificial Intelligence,
develop objectives and scenarios for the application of self-learning systems,
encourage collaboration in research and development,
position Germany as the leading supplier of technology for self-learning systems.
The Global Offshore Sailing Team is proud to announce that we will be organizing an Expedition Andaman Sea from April 14th to 22nd, 2022. This expedition is being held to promote international understanding and environmental awareness for this geopolitically important and naturally beautiful region.
One of the highlights of the expedition will be a wreath laying ceremony to honor and pay tribute to those who have worked for peace in this important geopolitical region and for the promotion of the conservation of the Andaman Sea’s beautiful nature. This ceremony will be an homage to the rich values and culture of Thailand and its people, whose engagement is key to the Andaman Sea.
We invite all individuals and organizations who are committed to these values to join us in this important expedition and contribute to our mission of promoting understanding and awareness in this important part of the world.
“Expedition Andaman Sea aims to promote international understanding and support international relations by creating awareness about the geopolitical importance of the Andaman Sea region. As part of this goal, the expedition will lay a wreath to honor and commemorate those who have served and engaged themselves for peace in the Andaman Sea. This gesture serves to underscore the importance of peace and stability in the region and the efforts of those who have worked towards this goal.”
Jochen Werne – Expedition Leader
„The Andaman Sea is a vital and diverse maritime ecosystem that is essential to the health and productivity of the region. From its abundant marine life to its stunning coral reefs, the Andaman Sea is a treasure worth protecting. The protection of this ecosystem is closely tied to the United Nations‘ sustainable development goals, and it is a major goal of Expedition Andaman Sea to promote these goals and the initiatives being undertaken to support them. Join us on this once-in-a-lifetime adventure and help us raise awareness about the importance of preserving the beauty and prosperity of the Andaman Sea for generations to come.“
Guido Zoeller – Co-Founder Global Offshore Sailing Team
After a challenging 2022 this year ends with HOPE due to a rally of technological innovation breakthroughs. Technological progress has the potential to help address many of the challenges facing the world today, including the energy crisis, the need for better education, and financial inclusion. Three of them shall be brought to your attention: 1. CLEAN ENERGY – Breakthrough in nuclear fusion technology; 2. EDUCATION – ChatGPT is changing the way to experience artificial intelligence; 3. PRIVACY & FINANCIAL INCLUSION – New compliant pathways for privacy and security in the blockchain-based financial ecosystem
Breakthrough in nuclear fusion technology
One area where technology is helping to address the energy crisis is through the development of nuclear fusion as a potential source of clean, abundant energy. Nuclear fusion is a process in which atomic nuclei combine to release energy, and it has the potential to provide a virtually limitless source of energy with low carbon emissions. While significant progress has been made in developing fusion technology, it is still in the early stages of development and has not yet been fully commercialized. However, the potential for nuclear fusion to help address the energy crisis makes it a promising area of research and development.
In December 2022 the National Ignition Facility (NIF) has successfully sparked a fusion reaction that released more energy than went into it. Even though there’s still a long way to go toward fusion as a clean energy source, this step can be considered as a major step forward.
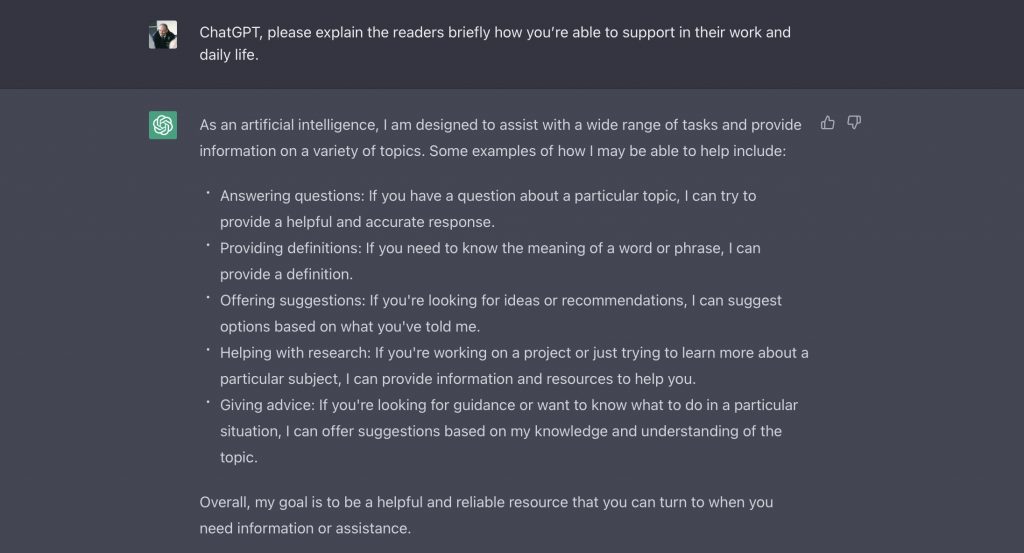
ChatGPT changes the way you experience artificial intelligence
ChatGPT, also known as OpenAI’s GPT-3 Chatbot API, is a natural language processing (NLP) tool developed by OpenAI. It is based on the GPT-3 model, which is a large, advanced AI language model that is capable of generating human-like text.
Overall, ChatGPT is changing the way we experience and interact with AI by making it easier to build and deploy chatbot applications that can understand and respond to user input in a natural, human-like way.
ChatGPT can be used to build chatbots and other NLP applications that can understand and respond to user input in a natural, human-like way. It is designed to be easy to use and integrate into existing systems, allowing developers to quickly build and deploy chatbot applications without the need for extensive training data.
One advantage of ChatGPT is its ability to understand and respond to a wide range of inputs and topics. It is trained on a large dataset of text and has the ability to generate coherent and contextually appropriate responses to a variety of inputs. This can make it a useful tool for building chatbots and other NLP applications that need to handle a wide range of queries and topics.
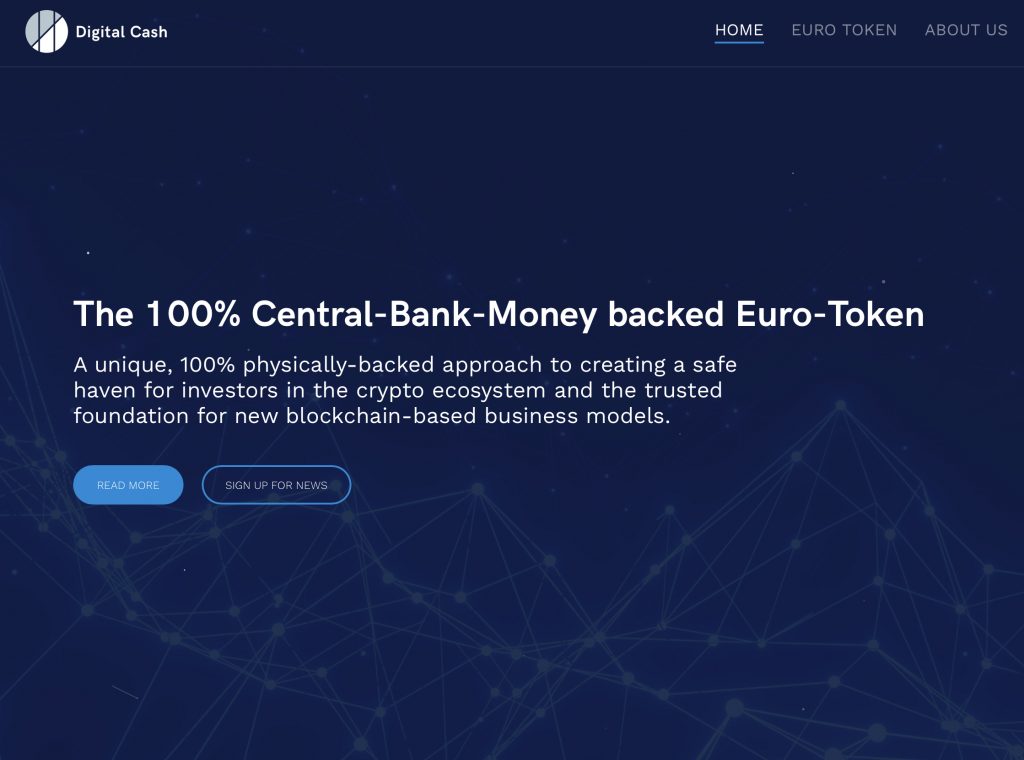
New compliant pathways for privacy and security in the blockchain-based financial ecosystem
Innovation in blockchain privacy can bring a number of advantages to the financial ecosystem, particularly in terms of increasing the security and confidentiality of transactions. By combining this innovation with a 100% collateralized stablecoin, it is possible to create a more secure and stable digital currency that can be used for a wide range of financial transactions.
One advantage of using a 100% collateralized coin is that it is pegged to a specific asset, such as a fiat currency or commodity, which helps to stabilize its value and reduce price volatility. This can make it more attractive to users, as it reduces the risk of loss due to price fluctuations. The German Digital Cash GmbH just announced to have issued the first 100% compliant, central-bank-money-backed, Made in Germany, Euro-coin on UniSwap, called Digital Cash Euro (DCEUR). READ MORE ON THE DCEUR HERE
In terms of privacy, a blockchain-based stablecoin that incorporates innovative privacy features can help to protect the confidentiality of transactions by making it more difficult for outsiders to track and monitor them. This can be particularly useful for financial institutions and individuals.
Researchers from German crypto blockchain-based payments fintech etonec and other organizations have proposed using zero-knowledge proofs to ensure regulatory compliance and privacy in stablecoins. They have created a design that allows fiat-based stablecoins to be used like cash, within limits.
Overall, the combination of a 100% collateralized stablecoin with innovative privacy features can bring a number of benefits to the financial ecosystem, including increased security, stability, and confidentiality.
Conclusion
Overall, technological progress has the potential to help address many of the challenges facing the world today, and it will likely continue to play a crucial role in finding solutions to these problems in the future.
December 2022 seems to be a good month in this respect. A month that shall give hope.
It was a great pleasure to meet again personally and be connected virtually with friends like Dr. Andreas Heindl and Dr. Johannes Winter who, like many others inside and outside this Digital Summit, dedicate their passion to the digitisation of Germany day after day. Their passion is the engine for Germany’s competitiveness and prosperity. Exchanges like today between Germany’s leading experts in the field of digitalisation and the German government are crucial for the country’s future innovation.
This was underlined today by Federal Chancellor Olaf Scholz and the ministers Robert Habeck, Volker Wissing, Nancy Faeser and Bettina Stark-Watzinger. A special motivation was given by Estonian Prime Minister Kaja Kallas and Japan’s Digital Minister Tarō Konō.
Congratulations to the organization committee and thank you for the kind invitation. Details can be found HERE
Digital Summit 2022
Germany’s digitisation continues to remain one of the main topics of the German government. The aim is to accelerate and promote digitisation processes and to exploit their potential to develop prosperity, freedom, social participation, and sustainability.
In this context, the Digital Summit remains the central platform for shaping the digital transformation with all parties involved. It focuses on the key fields of action within the digital transformation across ten topic-based platforms. The platforms and their focus groups are made up of representatives from business, academia and society who, between summit meetings, work together to develop projects, events and initiatives designed to drive digitisation in business and society forward. The Summit will serve to present the results of the work that has been done in the past, to highlight new trends and discuss digital challenges and policy approaches.
This year’s Digital Summit of the Federal Government will be held on 8 and 9 December 2022. The Federal Ministry for Digital and Transport and the Federal Ministry for Economic Affairs and Climate Action will jointly coordinate the summit’s preparation in the future. In the new legislature, new formats, concrete results and international impulses are to make it the driving force and showcase for digitisation in Germany and beyond.
Nomura Research Institute, one of the largest think tank in Japan has been appointed by the Government of Japan-Ministry of Economic, Trade, and Industry (METI) to promote the globalization of Japanese and Foreign companies in Japan and to understand the current business & living environment of Japan.
This study is to help the Government of Japan formulate better foreign policies in the future.
It’s with pleasure supporting this initiative, which aims to promote international understanding through exchange.
Read more at Nomura Research Institute (https://www.nri.com) and Japan-Ministry of Economic, Trade, and Industry (METI) (www.meti.go.jp/english/)
It was very inspiring to have the opportunity to participate in the workshop on responsible quantum technologies with some of the world’s most recognised experts in the field. Congratulations and thanks a lot to the organisation committee.
The second quantum revolution has been ongoing for more than two decades now and many countries around the globe have noticed the promises of these technologies. Just in the last decade, the number of publicly supported national initiatives grew from zero to more than 15, with globally more than 20 B€ of public investments allocated or planned. Both the number of new publications per year and patents granted on quantum technologies (QT) has also been climbing steadily for the last decade, so has been the number of start-ups being founded and established companies getting into the field. Finally, the field started receiving attention from private funding sources in recent years, which some have been calling the ‘quantum gold rush’. Within two decades, QT became a strong contender for a potential future industry from a topic that was mainly discussed in physics conferences.
All this rapid development triggered a sort of quantum ‘race’, where countries, companies, and institutions compete to become the first to achieve a checkpoint or to be the current best at some quantum benchmark. However, it is also noted by many that the real/transformative effects of QT on society will be in the long run. In this respect, we would like to initiate a discussion on responsibility and introduce QT as a noteworthy emerging topic for technology assessment (TA) studies.
This workshop aimed to be another step towards establishing connections between the QT and TA communities and to introduce some current discussions in the QT community to a new audience. It is organized as a collaboration between the QuTec project under KIT-ITAS, and the QUCATS Coordination and Support Action of the Quantum Flagship program.
The conference program consisted of panels such as:
Panel on Responsible Education and Workforce Development for QT
Moderator: Araceli Venegas-Gomez (QURECA)
Panelists: Tatjana Wilk (MCQST), Maria Luisa Chiofalo (University of Pisa), İlke Ercan (TU Delft)
Panel on RRI and Ethics in QT
Moderator: Pieter Vermaas (TU Delft)
Panelists: Oxana Mishina (CNR-INO), Carolyn Ten Holter (Oxford), Douglas K. R. Robinson (CNRS), Robert Whitney (Université Grenoble Alpes)
Panel: How to think responsibly on the geopolitics of QT?
Moderator: Astrid Bötticher (University of Jena)
Speakers: Pieter Vermaas (TU Delft), Matthias C. Kettemann (IQEL, University of Innsbruck/HIIG), Mira L. Wolf-Bauwens (IBM Research Europe)
It is with great sadness that we have been informed by our friends of the Royal Cinque Ports Yacht Club Dover of the death of a unique personality, sailor, leadership example, GOST member of honour and friend – Admiral of the Fleet, The Lord Boyce.
He will forever accompany us on board in our midst. May he rest in eternal peace.
Messages of Condolence and personal notes:
On a really sad note Lord Boyce who was the Lord Warden of the Cinque Ports and who many of us have met passed away yesterday. A really good and nice man who we are going to miss. Look up his obituary. We were very privileged to have him as a friend.
Bernard Sealy
Dear Skipper, that are really sad news. May he rest in peace forever. All our thoughts are with our English friends.
Götz Credé
…for us of the Global Offshore Sailing Team this is a big loss but for the faith that distinguishes us The Lord Boyce will always accompany and guide us in our future missions, by sea and by land.
Stefano Malvestio
He was the BEACON for GOST! Thank you!!
Bernd Lehmann
It is truly sad, but we are very lucky that we had him to invite and guide us through his parliament, the House of Lords!
Guido Zoeller
It was a true honor having met this kind Gentlemen
Dr. Benon Janos
Memorable moments with Admiral of the Fleet, the Lord Boyce and GOST